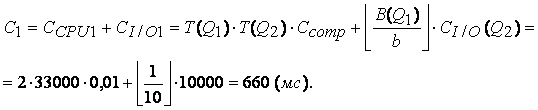
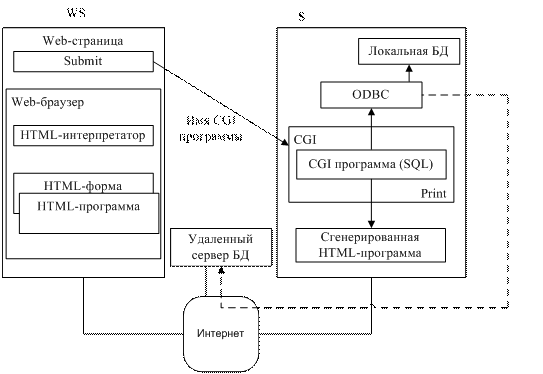
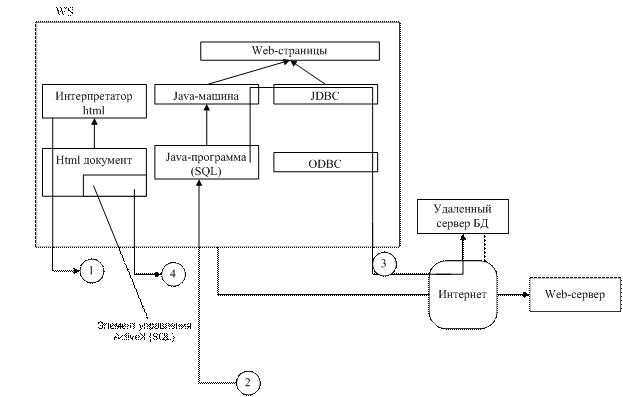
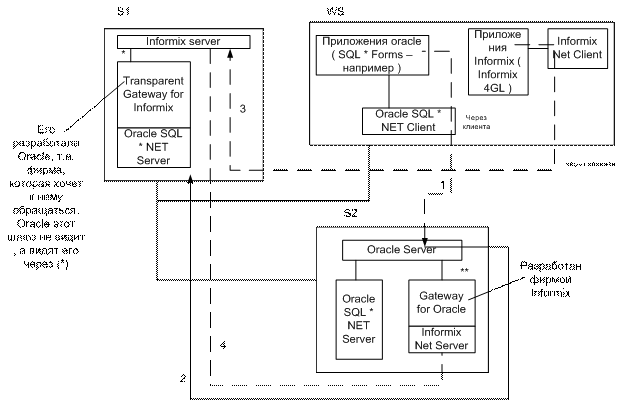
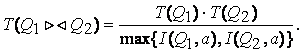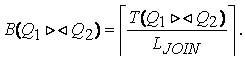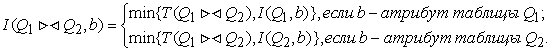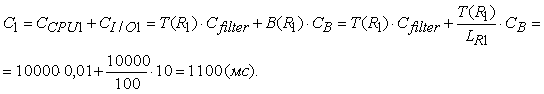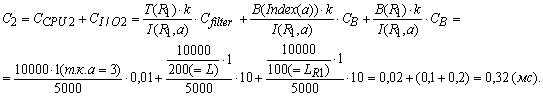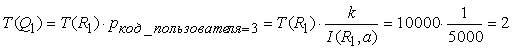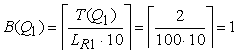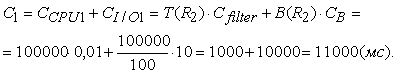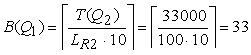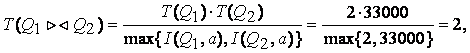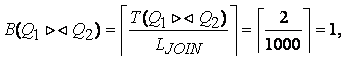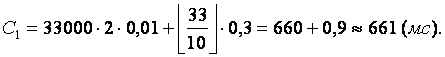Методология общесистемного
проектирования (МОП).
Лекция 1
Модели проектирования распределенных
систем обработки данных (РСОД).
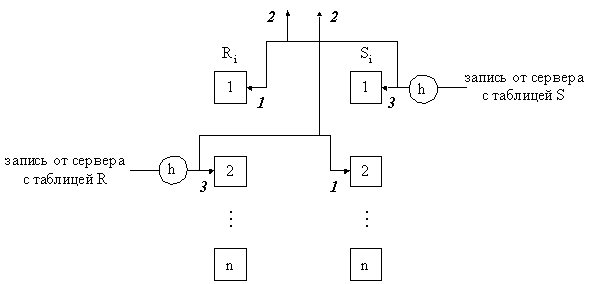
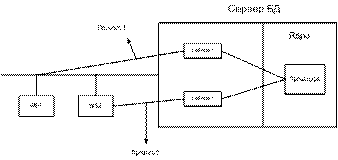
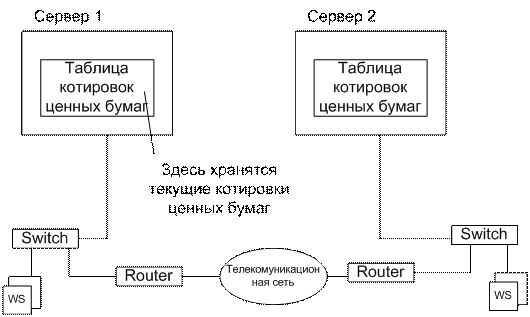
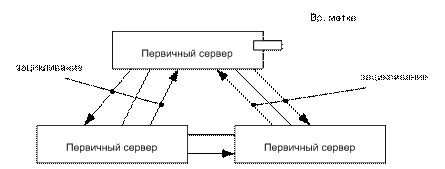
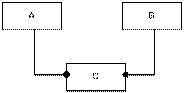
Пример РСОД:

Router необходим для гашения broadcast рассылок.
Предположим,
что с WS в Санкт-Петербурге формируется следующий запрос к БД:
НАЙТИ КЛИЕНТОВ БАНКА, У КОТОРЫХ ОСТАТОК НА СЧЕТЕ В САНКТ-ПЕТЕРБУРГЕ >=2000
у.е., А В МОСКВЕ >=1000 у.е. В виде SQL оператора запрос поступает на БД Сервера 2 и там
оптимизируется, при этом выполняются следующие задачи:
1.
Формирование
подзапроса к БД Сервера 1 (НАЙТИ КЛИЕНТОВ У КОТОРЫХ ОСТАТОК >=1000 у.е. И
ИМЕЮЩИХ СЧЕТ В САНКТ-ПЕТЕРБУРГЕ). Результат возвращается на БД Сервера 2.
2.
Формирование
подзапроса к БД Сервера 2 (НАЙТИ КЛИЕНТОВ, У КОТОРЫХ НА СЧЕТЕ В САНКТ-ПЕТЕРБУРГЕ
ИМЕЕТСЯ >=2000 у.е.). Этот запрос выполняется на Сервере 2.
3.
Полученные
результаты на этапах 1 и 2 соединяются по общим атрибутам.
4.
Результат
возвращается на станцию, подавшую запрос.
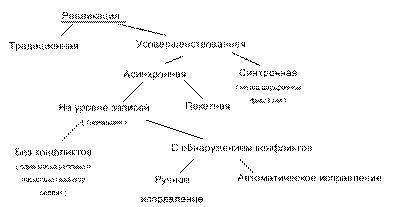
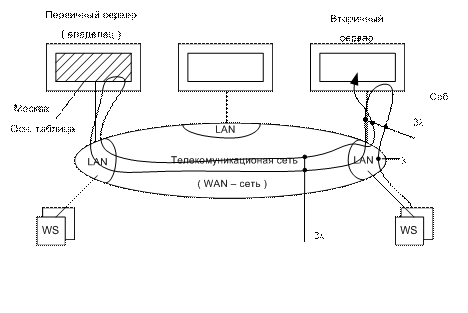
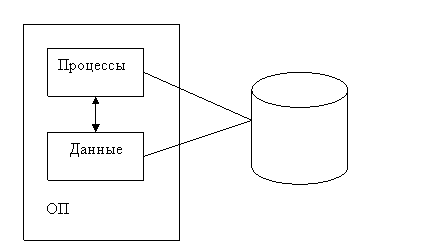
РСОД
– система, в которой ее данные и/или программа располагается в разных узлах
(серверах) сети и обеспечивает прозрачный (клиент не видит реализации)
доступ к данным.
В
настоящее время существует два подхода к проектированию РСОД:
1.
Структурный
2.
Объектно-ориентированный
Два
принципа структурного подхода:
1. Общая задача проектирования декомпозируется
на подзадачи по иерархии сверху вниз.
2.
Процедурный подход программирования.
Два
принципа объектно-ориентированного подхода:
1. Наличие объектов и связей между ними.
2. Используется ООП, а также объектные СУБД.
Недостатки
объектно-ориентированного подхода:
1. Некоторые ПО очень трудно представить в виде объектов
(экономика, медицина)
2. Существуют трудности в детальном описании схемы БД в
нотации UML.
Данный курс ориентирован на структурный подход!!!
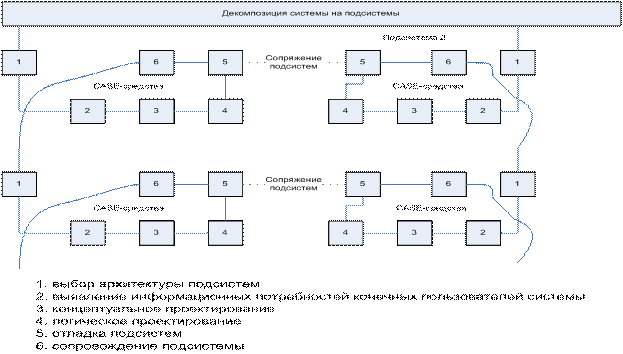
Модели проектирования СОД.
1.
Каскадная модель
(использовалась до середины 80х)
2.
Спиральная модель
(используется по настоящее время)
Каскадная модель проектирования СОД.
6. Сопровождение. |
Пилотный проект |

Краткое описание этапов каскадного
проектирования.
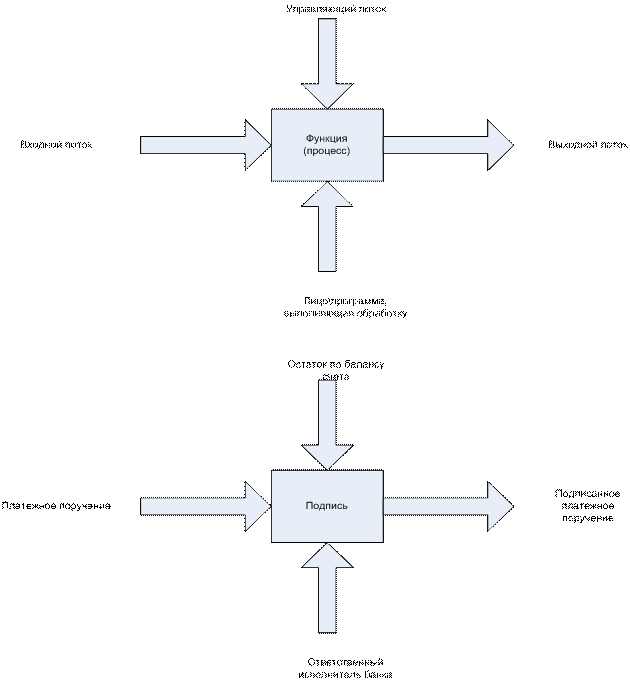
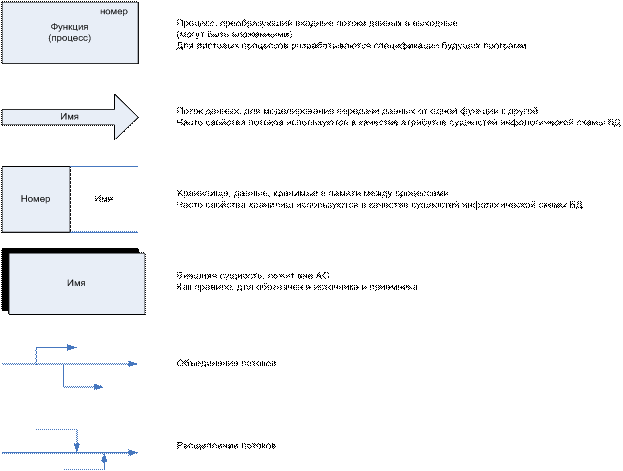
1. Функциональный грая ПО - граф, узлы которого
обозначают данные и процессы будущей системы. Дуги используются для обозначения
входных/выходных данных для процесса.
Пример:
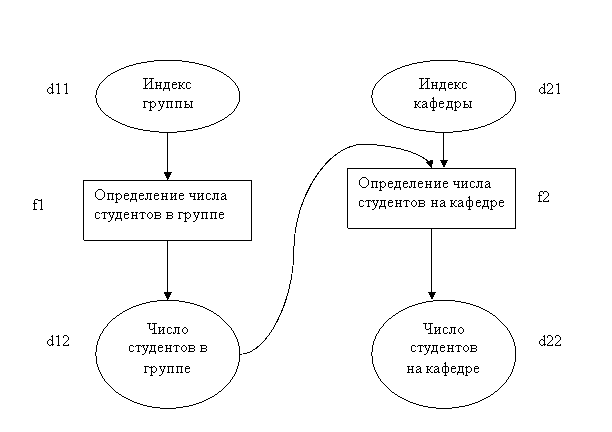
d22=f2(d12,d21)=f2(f1(d11),d21)
2. В функциональном графе данные и процессы объединены и
в принципе его достаточно для реализации будущей системы (см. формулу к
рисунку), но современные компьютеры есть машины Фон-Неймана, где предполагается
разделение процессов и данных.
Для реализации концептуальной модели проектировщик вынужден выделять из функционального графа данные и строить для них схему БД, а также выделять процессы и разрабатывать для них спецификацию и кодировать. Это является источником большинства ошибок проектирования.
Пример:
(Инфологическая модель БД в нотации Чена)
Спецификация процессов - входные и выходные данные
процессов, а также алгоритмическая связь между ними. Для описания спецификации
существуют различные методы: структурированный естественный язык (часто
используется), язык проектирования спецификации Flow-Form (визуальные
языки).
Концептуальный проект не зависит от
архитектуры!!!
Лекция 2
3. выбор архитектуры:
- Модель доступа к данным
- Комплекс технических
средств (выбор «железа»)
- Общесистемные пакеты
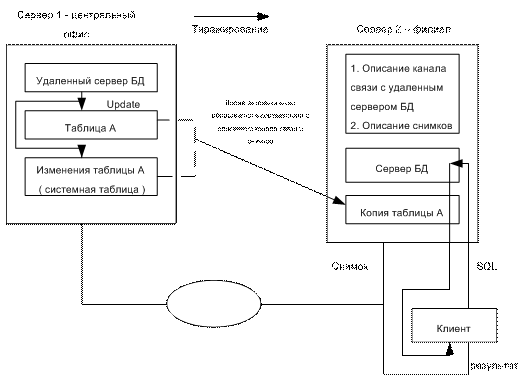
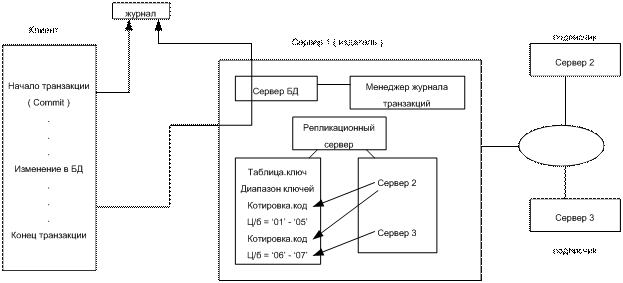
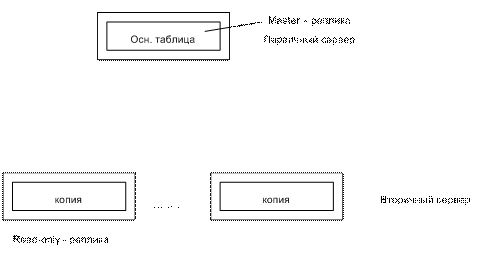
-Тиражирование данных
4. логическое проектирование
выполняется отражение
концептуального проекта в СУБД-ориентированную среду с помощью выбранных
оболочек программирования,
логический проект зависит от
архитектуры (можно считать временные характеристики)
Достоинства каскадной модели:
- проста, естественна, имеет
некоторую привязку к ГОСТу
Недостатки:
- достаточно продолжительный
цикл разработки по времени (система морально устаревает)
- доработка системы связана с
большим объемом перепрограммирования (из-за слабого использования CASE-средств)
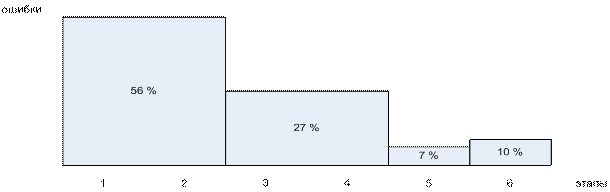
Результаты
исследований Д.Мартина (сер. 80х)
1я диаграмма: распределение
ошибок и просчетов по этапам проектирования, выявленных при сопровождении
системы
2я диаграмма: распределение
затрат на исправление ошибок и просчетов, выявленных при сопровождении
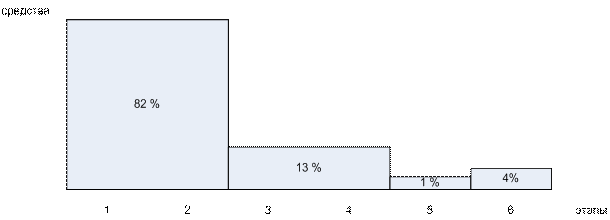
3я диаграмма: распределение
трудозатрат по этапам проектирования

Почти половина трудозатрат
приходится на устранение ошибок, допущенных на первых 2х этапах
На основании исследований
Мартин сформулировал законы:
1.
закон
неопределенности в информатике:
процесс
автоматизации задачи меняет представление пользователя об этой задаче, т.е.
пользователь решает задачу с использованием средств автоматизации иначе, чем без
них (пользователя надо использовать постоянно в процессе проектирования, а не
только в начале)
2.
чем больше
времени прошло с момента совершения ошибки до момента ее обнаружения, тем
больше средств необходимо для ее устранения (смотри диаграмму 2)
3.
программисты и
проектировщики не учатся на чужих ошибках, а только на своих
Для устранения недостатков
каскадной модели предложили спиральную модель.
Спиральная
модель проектирования
Содержание этапов совпадает с
аналогичными в каскадной модели, но в отличие от нее, этапы реализуются с
помощью CASE- средств ( Computer Aided
Software System Design) – использование этих
средств позволяет существенно снизить время реализации витка спирали
проектирования подсистем, но это профессиональные средства, непредназначенные
для конечных пользователей.
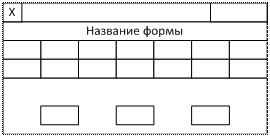
CASE- средства – этапы применения:
1.
с использованием
средств разрабатывается пилотный проект системы (экранные формы, без
детализации - привлекается конечный пользователь, указывающий недостатки экранных
форм)
2.
проектировщик
дорабатывает формы с учетом замечаний – снова привлекает пользователя, … , до
тех пор, пока не выработаются устойчивые спецификации
3.
с помощью языков
4GL приложение дорабатывается, пишутся скрипты и
обработчики
Выявление
информационных потребностей конечного пользователя
Используются 2 типа диаграмм:
- SADT (Structure Analysis and Design Technology)
- DFD (Data Flow Diagram)
SADT диаграммы
Используются, в основном, для
описания информационных потоков, существующих в рамках всей организации
(машинная и ручная обработка)
DFD
Используются для описания
функционирования АС предприятия, т.е. машинной обработки
Нотация Гейна-Саксона
Общая схема
выявления информационных потребностей конечных пользователей с использованием DFD
DFD образуют иерархию, каждая
диаграмма следующего уровня детализирует процесс на диаграмме предыдущего.
Для листовых процессов
разрабатываются спецификации программ.
Лекция 3
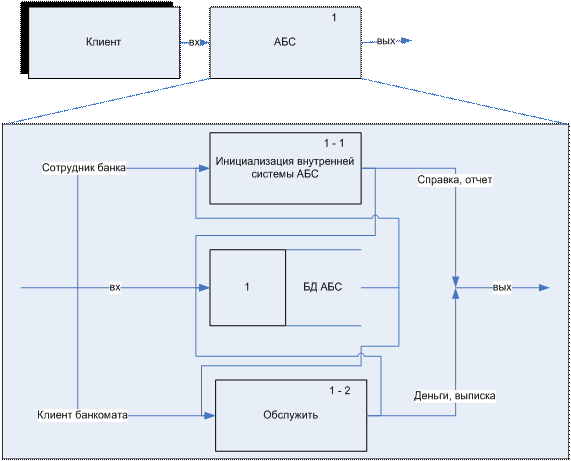
Пример построения DFD- диаграммы
Задача
Разработать фрагменты DFD-диаграммы системы, организующей работу банкомата по обслуживанию клиента по его пластиковой карте.
Предпосылки:
1) Пластиковая карта является дебетовой (можно снять деньги)
2) Используется карта с магнитной полосой, без чипа.
3) Авторизацию карт выполняет банк-эмитент (проверку реквизитов).
4) Банкомат, процессинговый центр и традиционная банковская система работает в режиме online(запрос-ответ)
1. Контекстная диаграмма.
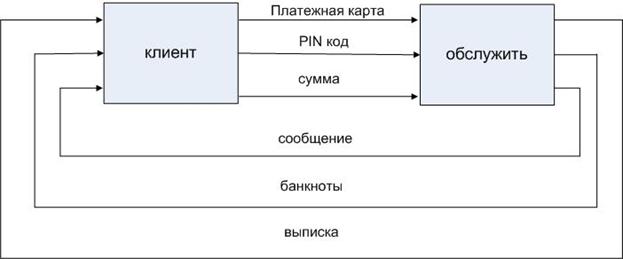
![]()
![]()
![]()
![]() 2.
Детализация процесса «обслужить»
2.
Детализация процесса «обслужить»
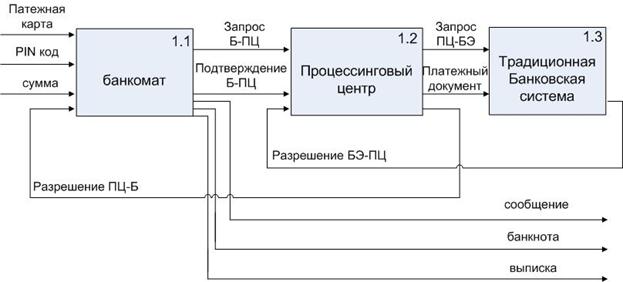
После ввода пластиковой карты, PIN-кода и суммы формируется запрос Б-ПЦ в процессиговом центре, который является связующим звеном между банкоматом и традиционной банковской системой. ПЦ формирует запрос (ПЦ-БЭ) в банк-эмитент. Банк-эмитент анализирует реквизиты пластиковой карты (PIN-код, сумма) и выдает разрешение БЭ-ПЦ. Процессинговый центр транслирует это разрешение в разрешение ПЦ-Б, которое передается банкомату. Банкомат выполняет требуемое действие (выдает деньги). После этого банкомат дает подтверждение в процессинговый центр (подтверждение Б-ПЦ).
Процессинговый центр извлекает из своей БД платежные документы (информация о проводках) и передает их в традиционную банковскую систему. В ней проводятся требуемые проводки по счетам и карточный счет разблокируется для следующих операций.
Замечание:
1) Платежная система-это ассоциация банков, объединившихся с целью выпуска и обслуживания пластиковых карт (Visa, Maestro…)
2) Банк может быть участником нескольких платежных систем.
3) Банкоматы, процессинговые центры и банковские системы обслуживания карт образуют распределенную систему. Её работа прозрачна для клиента (он не знает о транзакциях).
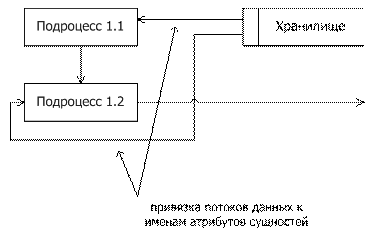
3. Детализация процесса «банкомат» (1.1)
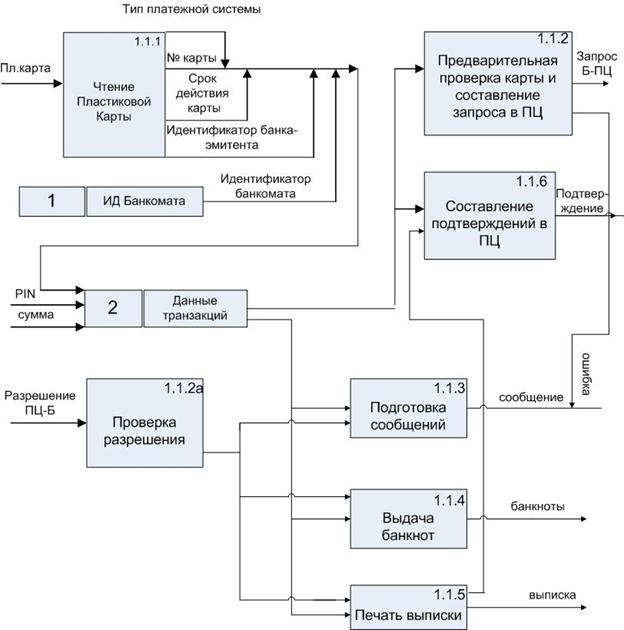
Тип платежной системы, номер карты, срок действия карты, ИД банка-эмитента, ИД банкомата, PIN-код и сумма объединяются в данные транзакций, которые запоминаются в хранилище 2. Эти данные используются при формировании запроса Б-ПЦ (1.1.2) для выполнения требуемых операций (1.1.3-1.1.5), а так же для составления подтверждения в ПЦ (1.1.6)
4. Детализация процесса в процессинговом центре (1.2)
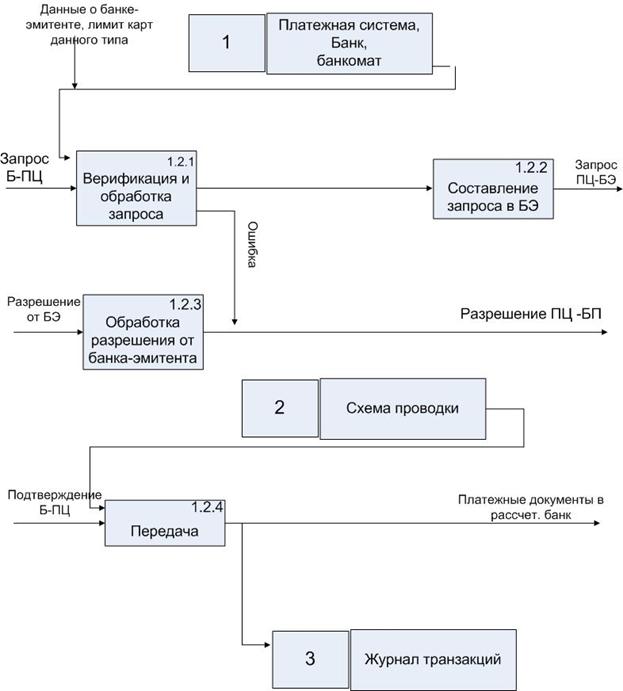
Процессинговый центр выполняет верификацию запроса от банкомата (1.2.1), формирует запрос в банк-эмитент (1.2.2), обрабатывает разрешение от банка-эмитента (1.2.3), а так же передает платежные документы в расчетный банк (1.2.4)
Схема расчетов
между банками
Для расчетов между банками используются корреспондентские счета ЛОРО и НОСТРО.
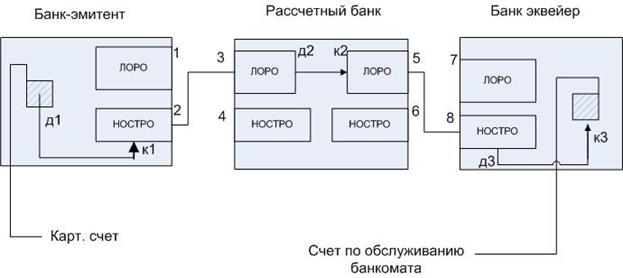
Расчетный банк – банк, в который поступили документы из процессингового центра (корреспондирующий).
Банк-эквайер – собственник банкомата.
2-3: НОСТРО-счет – корреспондентский счет расчетного банка открытый в банке-эмитенте.
ЛОРО-счет – счет расчетного банка открытый в нем для обслуживания банка-эмитента.
5-8: ЛОРО и НОСТРО счета, открытые для взаимных расчетов между расчетным банком и банком-эквайером.
Д – дебет – снятие
К – кредит – зачисление.
При поступлении платежных документов из процессингового центра выполняется следующая транзакция, её инициирует расчетный банк:
1) Проводка (д1,к1). Дебет по карт-счету, кредит по НОСТРО-счету в банке-эмитенте.
2) проводка (д2,к2). Дебет по ЛОРО-счету расчетного банка, кредит по ЛОРО-счету расчетного банка для банка-эквайера.
3) Проводка (д3,к3). Дебет по НОСТРО-счету банка-эквайера и кредит по счету обслуживаемого банкомата.
Эти действия образуют транзакцию. Все операции транзакции либо должны быть выполнены все одновременно, либо ни одна из операций обновления не должна быть выполнена.
5. Детализация процесса традиционной банковской системы
(1.3)
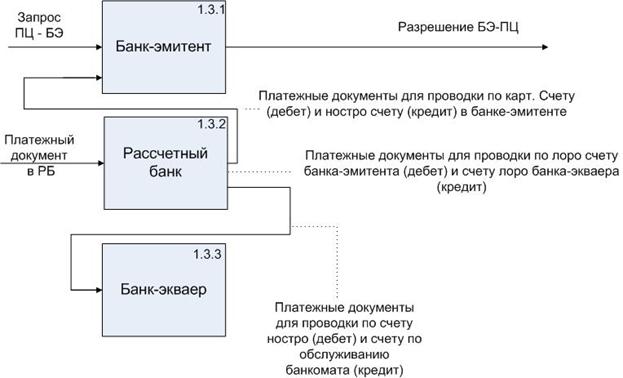
По запросу ПЦ-БЭ выполняется проверка реквизитов карты и выдается разрешение БЭ-ПЦ на выполнение операции.
На основании платежных документов выполняются требуемые проводки.
Примечание:
1) рассмотренные примеры диаграмм обслуживания пластиковых карт не единственные, возможны другие варианты, все зависит от того, что банки делегировали в процессинговый центр.
Например, возможны другие схемы. Результаты операции в банкомате передаются в банк-эквайер через ПЦ, а тот выставляет счет в банк-эмитент.
2) в рассмотренных диаграммах проводки по ЛОРО и НОСТРО счетам выполняются по каждой операции в банкомате, что очень не рационально, поэтому часто ля расчета используются клиринговые центры.
Лекция 4
Клиринговый центр.
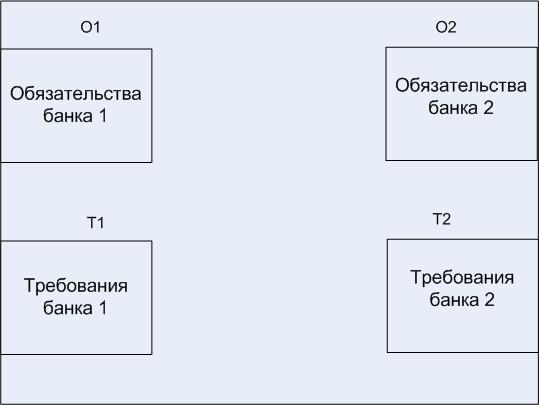
Обязательства – эта та сумма, которая перечислена банком другому банку.
Она может быть равна нулю.
Требования – сумма, которую другой банк должен данному банку.
∆ 2 = Т1-О2 - долг банка 2 банку 1
∆ 1 = Т2 – О1 – долг банка 1 банку 2
1) если ∆ 1 =∆ 2 то происходит взаиморасчет и никаких платежей не осуществляется.
2) если ∆ 1 > ∆ 2 Банку 2 предоставляется кредит клиринговым центром и гасится долг. Кредит равен ∆ 1 – ∆ 2
Программные пакеты, используемые для
построения DFD.
1) Designer 6i (Oracle)
Этот продукт позволяет автоматизировать все основные этапы витка разработки автоматизированной системы (этапы 2-6) кроме этапа выбора архитектуры.
Недостатки: разработанный пилотный проект может функционировать только в среде Oracle
2) Silverrun, PRO IV
Эта пара так же позволяет автоматизировать этапы 2-6 витка АС, но с помощью этих продуктов можно генерировать пакет для различных платформ (Oracle, Informix, Sybase)
3) BPwin
С помощью него можно строить DFD диаграммы, генерировать отчеты, имеет связь с пакетом Erwin на уровне импорта-экспорта данных.
Лабораторная работа № 1
1) с помощью пакета BPwin разработать DFD-диаграмму системы, организующей работу банкомата по обслуживанию клиента по его пластиковой карте (см. лекцию.)
2) сгенерировать отчет диаграмм Object report.
Требования к отчету:
1. Рисунки DFD-диаграмм и их краткое описание
2. Привести отчет Diagram Object Report
Литература Маклаков С.В. «Создание информационных систем».
Этап концептуального проектирования.
На этом этапе решаются следующие задачи:
1. Разрабатывается инфологическая схема БД
2. Разрабатывается спецификация будущих прикладных задач.
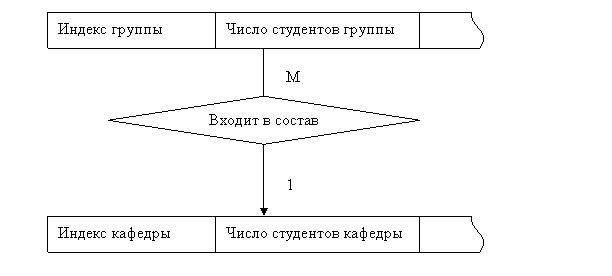
Проектирование инфологической схемы БД.
Для описания схем БД используется диаграмма «сущность- связь» (ERD Entity – relationship diagram)
Для разработки ERD используется следующая нотация:
1. Нотация Чена (используется для ручного проектирования информационных схем)
2. Нотация Барнера (используется для машинного проектирования схем БД Oracle)
3. Нотация IDE F1x (ERwin, PowerDesigner) ERwin позволят создавать инфологические схемы, а потом автоматически генерировать даталогические модели для более чем 20 СУБД.
имя
Описание инфологический схемы БД в нотации Чена.
– независимая сущность. Эта сущность может присутствовать в схеме БД в 2х случаях:
-сущность не является дочерней
-она является дочерней, но связанна с родительской сущностью, не идентифицирующей связью.

– зависимая сущность. Может присутствовать в схеме БД, только если эта сущность является дочерней и связанна с родительской сущностью идентифицирующей связью.

- обозначает связь между сущностями.
Характеристики связей приведены в следующей таблице.
|
|
Тип связи |
|
|
Свойства |
Идентифицирующая |
Неидентифицирующая |
|
Обозначения на диаграмме Гена |
Глагольная форма со знаком * |
Глагольная форма без знака * |
|
Куда добавляются ключ родительской сущности при создании дочерней 1:М (1 – родительская; М - дочерняя) |
К ключевым атрибутам дочерней сущности |
К не ключевым атрибутам дочерней сущности |
|
Пример ссылочной целостности: 1. child delete 2.child insert 3. child
update 4.parent
delete 5. parent
insert 6. parent
update |
|
|
Пример построения инфологической схемы БД
Задача:
Описать инфологическую схему фрагмента БД процессингового центра в нотации Чена. См. диаграмму DFD детализированный процесс 1.2
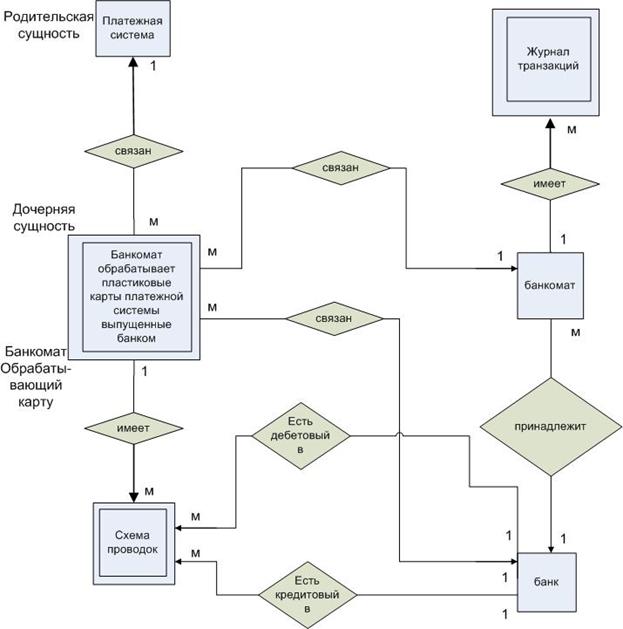
Здесь представлена инфологическая схема БД без описания атрибутов.
Примечание:
1) Здесь звездочка означает идентифицирующую связь. Это означает что ключ родительской сущности (1) добавляется ключевым атрибутам дочерней сущности (м). Это бывает необходимо, если ключевые атрибуты дочерней сущности в совокупности не являются уникальными (ключ всегда уникален).
2) Отсутствие звездочки в обозначении связи означает, что ключ родительской сущности (1) добавляется не к ключевым атрибутам (м). Это следует делать, если ключевые атрибуты дочерней сущности в совокупности являются уникальными.
3) Не идентифицирующая связь является предпочтительной, так как позволяет минимизировать число атрибутов в ключе дочерней сущности.
Лекция 5
Действия
(1) и (2) обеспечивают возможность связи сущностей по общим атрибутам, также
обеспечивают возможность объединения сущностей без потерь. Указанные средства
часто выполняются автоматически.
Атрибуты
сущностей БД.
|
Платежная
система |
#
Ключ платежной системы Наименование Лимит наличных |
|
Банк |
#
Ключ Банка БИК Наименование Адрес к/с в РКЦ № Лицензии |
|
Банкомат |
#
Ключ Банкомата Ключ банка v № Банкомата Лимит Банкомата Текущее число банкнот |
|
Бок |
#
Ключ БОК Ключ платёжной системы v Ключ Банка v Ключ Банкомата v |
|
Журнал
транзакций |
#
Номер операции #
Дата #
Ключ банкомата v Номер пластиковой карты Банк иметент Сумма |
|
Схема
проводки |
#
Номер проводки транзакции #
Ключ Бок Ключ
банка(дебет) v Признак счёта дебет (0-лора, 1-Ностра, 2
–карт – счёт) Ключ банка(кредит) v Признак
счёта кредит (0-лора, 1-Ностра, 2 –карт – счёт) Формула
расчёта суммы |
Для
уменьшения числа атрибутов в ключе можно использовать последовательность, а
отмеченные атрибуты сделать неключевыми.
#
- Ключевые атрибуты
v – атрибуты наследованные от родительских сущностей
Пример формирования платёжного документа
в расчётный банк по атрибутам «Схема проводки».
Пусть
записи «Схема проводки» имеют следующий вид:
·
Номер проводки
·
Ключ БОК
·
Ключ Сбербанка
·
2 – карт-счёт
·
ключ Банка Москвы
·
2 – счёт по
обслуживанию банкомата
·
102 – 100% сумма
+ 2% комиссия
Предположим,
пользователь карточки сбербанка запросил в банкомате Банка Москвы сумму равную
1000, тогда процессинговый центр на основании описания записи сформирует
следующий платежный документ, который будет передан в расчётный банк.
ДЕБЕТ:
Бик сбербанка
Номер
пластиковой карты
КРЕДИТ:
Бик Банка Москвы
Номер
банкомата
СУММА:
1020руб.
Отличия
нотации Чена от ErWin
|
Нотация
Чена |
ErWin |
|
1. Обозначение сущности
|
|
|
2. Обозначение связи а)Идентифицирующая
б) неидентифицирующая
в)М:М
|
Logical
Phisical
|
|
3) Категоризация сущностей
|
|





При
разработки инфологической схемы проектировщик руководствуется тремя
абстракциями.
Агрегация
– это объединение реквизитов в отдельный экземпляр.
Реквизиты Код01
VISA Лимит 2000
Агрегат ![]()
Обобщение
– это объединение агрегатов в сущность.
Агрегат ![]()
![]()
Сущность ![]()
Ассоциация
– это связь между сущностями
Лабораторная работа №2
1. Разработать с помощью ErWin Logical(инфологическую)
схему БД процессингового центра.
2. Разработать physical
(даталогичекскую) схему БД для oracle 8i/
3. Сгенерировать DDL сценарий с
описанием объектов БД
Отчёт
Рисунки со схемами
и их краткое описание и последовательность разработки. В приложении DDL –
сценарий.
Лекция 6
Приложение – прикладная программа, разрабатываемая в процессе
проектирования.
Спецификация программы – входные и выходные данные программы и алгоритмы
связи между ними.
В
настоящее время для создания спецификаций используют два основных способа:
1. Структурированный
естественный язык;
2. Визуальные
языки описания (flow
- форм).
Структурированный естественный язык
Программу любой сложности можно описать с помощью трёх
конструкций:
1. Последовательность
конструкций.
конструкция
конструкция
…
конструкция
2.
Конструкция
выбора.
ЕСЛИ условие, ТО
конструкция
ИНАЧЕ
конструкция
КОНЕЦ ЕСЛИ
3.
Конструкция
итерации.
ДЛЯ условие
конструкция
КОНЕЦ ДЛЯ
Здесь
Конструкция – это либо элемент ВЫПОЛНИТЬ действие,
либо одна из вышеперечисленных
конструкций 1-3.
Часто слово ВЫПОЛНИТЬ опускают.
Пример использования
структурированного естественного языка.
Задача: Описать спецификации процесса
«проверка разрешения» (процесс 1.1.2 на диаграмме потоков данных «Банкомат»).
Описание спецификации:
@ ВХОД Разрешение
ПЦ-Б
@ ВЫХОД Признак разрешения для банкомата
(0
– есть разрешение, 1 – нет, 2 – ожидание разрешения от ПЦ)
@ СПЕЦ. ПРОЦ. Проверка разрешения ПЦ-Б
ЕСЛИ
Разрешение ПЦ-Б = true, ТО
выйти(0)
ИНАЧЕ выдать
сообщение об ошибке
ЕСЛИ ошибка в
пароле, ТО
проверить
счётчик_1 на max,
запросить
пароль,-
увеличить
счётчик_1 на 1,
обновить
данные транзакции,
«повторить
функцию предварительной проверки карты и состояния запроса в ПЦ» (1.1.2),
выйти(2)
ИНАЧЕ
ЕСЛИ
ошибка в сумме, ТО
проверить
счётчик_2 на max,
запросить
сумму,
увеличить
счётчик_2 на 1,
обновить
данные транзакции,
«повторить
функцию предварительной проверки карты и состояния запроса в ПЦ» (1.1.2),
выйти(2)
ИНАЧЕ
удалить
карту из банкомата
КОНЕЦ
ЕСЛИ
КОНЕЦ ЕСЛИ
КОНЕЦ ЕСЛИ
1. SELECT по которому заполняется таблица;
2. Требования
к клавишам;
3. Требования
к редактированию полей
Нажатие клавиши Ввод
…
Нажатие клавиши Выйти
…
Визуальные языки проектирования
спецификаций (flow - форм)
Элементы
языка flow-форм:
1.
|
конструкция |
|
конструкция |
|
… |
|
конструкция |
2.
|
ЕСЛИ |
условие |
|
|
ТО |
|
|
|
|
|
|
|
ИНАЧЕ |
|
3.
|
ДЛЯ |
условие |
|
|
||
Здесь
Конструкция – это либо элемент ВЫПОЛНИТЬ действие,
либо одна из вышеперечисленных
конструкций 1-3
с
учётом графического изображения.
Часто слово ВЫПОЛНИТЬ опускают.
Пример использования flow – форм.
Задача: см. предыдущий пример. В виде flow – форм.
Описание
спецификации:
|
ЕСЛИ |
Разрешение
ПЦ-Б = true |
|||||||||||||||||||||
|
ТО |
|
|||||||||||||||||||||
|
|
|
|||||||||||||||||||||
|
ИНАЧЕ |
|
|||||||||||||||||||||
Организация проектирования систем с
помощью пакета Designer 2000/6i
Процесс проектирования включает следующее шаги:
1.
Разработка контекстной диаграммы потоков
данных Process Modeler
Наглядное описание поведения системы

С каждым процессом или потоком данных можно связать
объект мультимедиа (например микрофильм).
2.
Разработка
диаграммы Сущность-Связь (диаграмма Бахмена)

3.
Разработка
диаграмм потоков данных (DFD) и диаграмм Function Hierarchy Diagram (FHD).
Function Hierarchy Diagram (FHD) автоматически генерируется на основе контекстных
диаграмм потоков данных и диаграмм, разработанных на шаге 3. FDH используется
для описания будущих меню системы.
Пример
FHD

В FHD
можно включать новые процессы, и они появятся в диаграммах потоков данных, но
без связей.
4.
Разработка
даталогической схемы БД и приложений (Design Editor).
Шаги:
1.
Генерация
даталогической схемы БД.
Data Diagrams.
Уточнение характеристик таблиц, индексов…
2.
Генерация
модуля.
Module Diagrams. Схема генерации модулей:
Модулю соответствует 1 DFD. Система выделяет хранилище, привязки, атрибуты в
потоках данных и генерирует форму.
Процесс DFD (процесс 1)
Module Logic Navigator генерирует скрипты,
обрабатывающие те или иные события.
Этап
логического проектирования
На этом этапе выполняется отражение
концептуального проекта в СУБД-ориентированную среду, т.е. на основе
инфологической схемы БД разрабатывается даталогическая схема БД, т.е.
генерируется DDL сценарий.
На основании спецификации программы
разрабатываются коды в выбранной оболочке программирования.
Разработка
даталогической схемы БД
Решаются задачи:
1.
Выполняется
оптимизация схемы БД.
2.
Уточняются
характеристики таблиц и атрибутов (имена, типы полей, индексы).
3.
С
помощью CASE-средств выполняется генерация схемы БД (DDL-сценарий).
Оптимизация
схемы БД
Основная задача – разработать алгоритм «хорошей» БД.
Основы
реляционной алгебры
1.
Определение
схемы отношений
Схема отношения – поименованное
множество атрибутов.
R = (A1, … An)
Ai = (i =1,n)
Пример:
R = (имя1, адрес, товар, цена) = (A1,
A2, A3, A4)
имя – id поставщика;
адрес – адрес поставщика;
товар – наименование поставляемого
товара;
цена – цена за единицу поставляемого
товара;
(имя, товар) – ключ схемы отношения.
Степень схемы отношения – количество
атрибутов в схеме.
Лекция 7
Отношение (экземпляр отношений) – конкретная таблица с
заданной схемой отношения.
Отношения
будем обозначать строчными буквами.
Схему
отношения будем обозначать заглавными буквами.
Пример
|
имя |
адрес |
товар |
цена |
|
АО «х» |
г. Москва, ул. у, д. z |
сахар |
25 |
|
АО «х1» |
г. Москва, ул. у1, д. z 1 |
карамель |
30 |
![]() Схема отношения
Схема отношения
![]()
отношения
Кортеж – строка отношения.
Определение схемы БД
Пусть А – множество всех атрибутов предметной области (универсальная схема отношения).
R1, … , Rn – схемы отношения такие, что ![]() .
.
В этом случае говорят, что r = (R1, … , Rn) – схема БД.
Пример
А = (имя, адрес, товар, цена)
R1 = (имя, адрес)
R2 = (имя, товар, цена)
R1 È R2 = А
Следовательно, r = (R1, R2) – схема БД.
Основная задача последующего изложения – построение «хорошей» схемы БД.
Пример «плохой» схемы БД
Предположим задана универсальная схема отношения.
А = (имя, адрес, товар, цена)
R1 = А
Поэтому r = (R1) – схема БД.
Она
обладает следующими недостатками:
1. избыточность
Адрес поставщика повторяется для каждого поставляемого им товара.
2. потенциальная противоречивость
При изменении адреса поставщика его необходимо изменить во всех строках отношения, куда он входит.
3. аномалия включения записи
Для данной схемы отношения R1 пара атрибутов (имя, товар) – ключ.
Как правило, при включении новой записи атрибуты, входящие в ключ, не могут быть пустыми. Следовательно, нельзя включить в БД имя поставщика, если он не поставил никакого товара.
4. аномалия удаления
При удалении всех товаров, поставляемых поставщикам, теряется вся информация о поставщике.
Первопричина этих недостатков состоит в том, что схема отношения не находится в 3-ей нормальной форме. Это одно из свойств «хорошей» схемы БД.
Пример «хорошей» схемы БД
А = (имя, адрес, товар, цена)
R1 = (имя, адрес)
R2 = (имя, товар, цена)
r = R1 È R2
В этом случае схема БД r не обладает вышеуказанными недостатками. Это означает, что R1 и R2 находятся в 3-ей нормальной форме.
Основные
операции реляционной алгебры
1. Объединение 2-х отношений
r3 = r1 È r2 – отношение, каждый кортеж которого принадлежит либо отношению r1, либо r2.
|
A1 |
A2 |
|
1 |
2 |
|
3 |
4 |
r1 =
2.
|
A1 |
A2 |
|
5 |
6 |
|
1 |
2 |
r2 =
|
A1 |
A2 |
|
1 |
2 |
|
3 |
4 |
|
5 |
6 |
r3 =
В реляционной алгебре дублирование кортежей не допускается.
r1 и r2 должны обладать одинаковыми схемами отношения.
2.
Разность отношений
r3 = r1 - r2 – отношение, каждый кортеж которого принадлежит отношению r1, но не принадлежит r2.
r1, r2 – см. выше
|
A1 |
A2 |
|
3 |
4 |
r3 =
3.
Пересечение
отношений
r3 = r1 Ç r2 – отношение, каждый экземпляр которого принадлежит и отношению r1, и отношению r2.
r1, r2 – см. выше
|
A1 |
A2 |
|
1 |
2 |
r3 =
4.
Декартово
произведение
Пусть R и S – две схемы отношения со степенями k1 и k2 (степень – число атрибутов в схеме отношения).
r, s – соответствующие экземпляры отношений.
Тогда t = r ´ s – декартово произведение, т.е. отношение со степенью k1 + k2, каждый кортеж которого получается путем конкатенации кортежей из r и s.
Порядок кортежей в отношениях r и s неважно.
|
A1 |
A2 |
|
1 |
2 |
|
3 |
4 |
r =
|
A1 |
A3 |
|
5 |
6 |
|
7 |
8 |
s =
|
R.A1 |
R.A2 |
S.A1 |
S.A3 |
|
1 |
2 |
5 |
6 |
|
1 |
2 |
7 |
8 |
|
3 |
4 |
5 |
6 |
|
3 |
4 |
7 |
8 |
t = r ´ s =
5. Проекция отношений на некоторое подмножество
атрибутов
![]() - отношение, каждый кортеж которого состоит из
значений атрибутов A1..Ak кортежа из r.
- отношение, каждый кортеж которого состоит из
значений атрибутов A1..Ak кортежа из r.
|
A1 |
A2 |
A3 |
A4 |
|
1 |
2 |
3 |
4 |
|
7 |
8 |
9 |
10 |
|
3 |
4 |
5 |
6 |
|
3 |
4 |
7 |
6 |
r =
|
A1 |
A2 |
|
1 |
4 |
|
7 |
10 |
|
3 |
6 |
![]() =
=
6. Селекция
![]() -отношение, каждый кортеж которого принадлежит r и удовлетворяет условию F.
-отношение, каждый кортеж которого принадлежит r и удовлетворяет условию F.
|
A1 |
A2 |
|
1 |
2 |
|
9 |
8 |
|
3 |
3 |
r =
|
A1 |
A2 |
|
1 |
2 |
|
3 |
3 |
![]() =
=
7. Естественное соединение
![]() , r и s – экземпляры отношений со схемами R и S.
, r и s – экземпляры отношений со схемами R и S.
Определение следует из правил его построения:
1) построить
декартово произведение ![]() ;
;
2) из
декартова произведения выбрать кортежи, удовлетворяющие условию: ![]()
![]() - атрибуты, общие в
схемах отношений R и S.
- атрибуты, общие в
схемах отношений R и S.
3)
удалить дублирующиеся столбцы ![]() и получим требуемое
отношение t.
и получим требуемое
отношение t.
|
A1 |
A2 |
A3 |
|
1 |
2 |
3 |
|
4 |
6 |
7 |
r =
|
A1 |
A2 |
A4 |
|
1 |
2 |
7 |
|
8 |
9 |
10 |
s =
Построить соединение ![]()
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
1 |
2 |
7 |
√ |
|
1 |
2 |
3 |
8 |
9 |
10 |
|
|
4 |
6 |
7 |
1 |
2 |
7 |
|
|
4 |
6 |
7 |
8 |
9 |
10 |
|
1) ![]() =
=
![]()
![]()
|
1 |
2 |
3 |
1 |
2 |
7 |
2)
|
A1 |
A2 |
A3 |
A4 |
|
1 |
2 |
3 |
7 |
3) t =
Теория нормализаций схем отношений
1) Функциональная
зависимость
Пусть R определение
функциональной зависимости. ![]() - универсальная схема отношений, т.е. схема состоит из всех
атрибутов предметной области.
- универсальная схема отношений, т.е. схема состоит из всех
атрибутов предметной области.
X и Y – некое подмножество этой схемы;
X →Y (Х функционально определяет Y), если в любом экземпляре r не существует двух кортежей, совпадающих по атрибутам Х и не совпадают по атрибутам Y.
Пример
Задана универсальная схема отношений:
R=(имя, адрес, товар, цена)= (А1, А2, А3, А4)
и функциональные зависимости:
А1 → А2, А1
А3→ А4
Пусть в БД хранится единственный экземпляр данной схемы:
|
A1 |
A2 |
A3 |
A4 |
|
АО «Х» |
г. Москва, ул. y, д. z |
Сахар |
25 |
|
АО «Х» |
г. Москва, ул. y, д. z |
Карамель |
30 |
|
АО «Х» |
г. Москва, ул. y, д. z |
Пастила |
40 |
r =
А1 А3→ А4 имеет место, так как нет кортежей, которые совпадали бы по этой паре атрибутов (по X и Y).
2) Замыкание множества функциональных зависимостей
Пусть R – универсальная схема отношения;
F – заданное множество функциональных зависимостей на этой схеме.
Замыканием F назовем множество функциональных зависимостей, которые логически следуют из F.
Функциональная
зависимость логически следует из F, если её можно получить с помощью аксиом Армстронга.
Обозначается F+ .
Аксиомы
Армстронга (правила
вывода)
1) Аксиомы рефлексивности
Если ![]() , то X →Y
, то X →Y
2) Аксиома пополнения
Пусть X →Y, ![]() (Z может быть Ø)
(Z может быть Ø)
Тогда ![]() (XZ
→YZ)
(XZ
→YZ)
3) Аксиома транзитивности
Если X →Y, Y→Z, то X →Z
Лекция 8
Пример построения замыкания.
(А,В,С)
F=(АàB, BàС)
F+-?
1) Построение тривиальных функциональных зависимостей:
AàA, BàB, CàC, ABàA, ABàB, ACàA, ACàC, BCàC, BCàB, ABCàA, ABCàC, ABCàB, ABCàAC, ABCàAB, ABCàBC, ABCàABC, ABàAB, ACàAC, BCàBC
2) Используем вторую аксиому Армстронга
AàAB
АСàBC
BàBC
ABàAC
ACàABC
ABàABC
3) Используем третью аксиому Армстронга
Т.к. АàB, BàС, то AàC
Аналогично,
ABàBC, AàAC, AàABC
Лемма
Справедливы следующие правила:
1) Правило объединения
Если множество атрибутов Х определяет множество атрибутов У (XàY) и XàZ, то XàYZ
2) Правило декомпозиции:
Если XàY, ZÍY, то XàZ
3) Правило псевдотранзитивности:
Если XàY, WYàZ,то WXàZ
Доказательство:
1. XàХY (пополняем атрибутом Х первую зависимость)
XYàYZ (пополняем атрибутом Y вторую зависимость)
По третьей аксиоме Армстронга получаем XàYZ
2. Т.к. XàY, ZÍY, то по первой аксиоме Армстронга YàZ. Тогда по 3 аксиоме получаем: XàZ
3.
WYàZ (по условию). Тогда по 3 аксиоме получаем: WXàZ
Теорема
Аксиомы Армстронга являются надежными и полными.
Надежность: если функциональная зависимость выводится с помощью аксиомы Армстронга, то она справедлива в любых экземплярах отношений, где справедливы исходные функциональные зависимости.
Полнота: если имеет место функциональная зависимость XàY, то она обязательно может быть выведена с помощью аксиом Армстронга.
Количество функциональных зависимостей, входящих в замыкание F+, может быть очень велико, даже если число исходных функциональных зависимостей незначительно.
Пример
F={XàA1…. XàAn}
Из правила объединения следует, что справедлива функциональная зависимость XàY, где Y- произвольное подмножество множества (A1…. An). Таких комбинаций может быть 2n.
Поэтому в теории нормализации схем отношений напрямую замыкание F+ не строится, но есть подход, позволяющий определить, принадлежит ли функциональная зависимость XàY замыканию F+. Этот подход основывается на понятии замыкания множества атрибутов.
Замыкание множества
атрибутов.
Пусть R- универсальная схема отношений. Замыканием множества атрибутов Х, принадлежащего R (XÍR), называется множество атрибутов Ai1…. Aik, таких, что справедливо следующее выражение:
(XàAi1…. XàAik) ÍF+.
Замыкание множества атрибутов обозначается через Х+.
Правило
Чтобы проверить, принадлежит ли функциональная зависимость XàY замыканию F+ (XàY ÍF+), сначала строят Х+ и если Y Í Х+, то значит XàY Í F+.
Основная задача заключается в построении алгоритма замыкания множества атрибутов.
Алгоритм
построения замыкания множества атрибутов.
Это итерационная процедура, включающая следующие шаги:
- i:=0, X0+=X – замыкание множества атрибутов на i-ом шаге.
- Положить X+i+1:= X+iÈV, где V – множеств атрибутов такое, что в F имеется функциональная зависимость Y→Z, для которых YÍ X+i , а VÍZ.
- X+i+1= X+i – это есть X+:= X+i , иначе i:=i+1 и перейти к шагу 2.
Пример замыкания множества атрибутов.
R=(A,B,C,D,E,G),
F=(AB→C, C→A, BC→D. ACD→B, D→EG, BE→C, CG→BD, CE→AG)
X=BD, X+ - ?
- X0+≔BD
- и 3. Оформим в виде таблицы:
|
i |
Y→Z, для которых YÍ X+i |
VÍZ |
X+i+1≔ X+iÈV |
|
0 |
D→EG |
EG |
EGBD X+1 |
|
1 |
BE→C |
C |
EGBDC X+2 |
|
2 |
C→A,
BC→D, CG→BD, CE→AG |
A |
EGBDCA X+3 |
|
3 |
AB→C,
ACD→B |
|
EGBDCA X+4 |
Т.о. (BD)+ = EGBDCA *Þ
(BD→E,
BD→G, BD→B, BD→C, BD→D, BD→A) Ì F+
**
* и ** эквивалентны.
Покрытие множества функциональных зависимостей.
Определение покрытия. Пусть F и G - множества функциональных зависимостей. G называют
покрытием F, если их
замыкания совпадают. G+
= F+
Определение минимального покрытия. Покрытие G называется минимальным, если оно содержит:
a) минимальное число функциональных зависимостей
b) минимальное число атрибутов в левой и правых частях функциональных зависимостей.
Алгоритм построение минимального покрытия G для множества
функциональных зависимостей F.
1) Кажду функциональную зависимость из F заменить на совокупность функциональных зависимостей, каждая из которых содержит 1 атрибут в правой части. Полученное множество функциональных зависимостей обозначим через G.
2) Для каждой функциональной зависимости (X→A)ÎG выполнить следующие дествия:
a. Проверить, принадлежит ли данная функциональная зависимость (G-X→A)+ и если да, то исключить её из G (т.к. её можно вывести из меньшего числа функциональных зависимостей).
Примечание. Чтобы выполнить эту проверку, необходимо построить замыкание множества атрибутов на множестве функциональных зависимостей (G-X→A) и если AÎ(G-X→A)+ и проверить, принадлежит ли A…
b. Для каждого собственного подмножества Z<X проверить Z→AÎG+ , и если да, то заменитьт зависимость X→A на Z→A (с меньшим числом атрибутов), повторить п.2b, где вместо X→A выступает Z→A.
Примечение. Чтобы
проверить, принадлежит ли Z→AÎG+, необходимо
построить Z+ для множества функциональных зависимостей G и
проверить AÎG+ , и если да, что по
определению Z→AÎG+
3) Зависимости в G с одинаковой левой частью объединить в 1 функциональную зависимость (см. правило объединения доказанных выше лемм).
п.п.1,2 алгоритма обеспечивают минимальное число атрибутов в левой и правой частях каждой функциональной зависимости из G. п.3 обеспечивает минимальное число функциональных зависимостей G.
Пример построения минимального покрытия.
Пусть задана универсальная схема отношений R=(A,B,C,D)
F=AB→CD, BC→A, BC→D, C→D.
Построить минимальное покрытие G от F.
1) Заменить каждую функциональную зависимость (правило декомпозиции) G=(AB→D, AB→C, BC→A, BC→D, C→D).
AB→D, G-AB→D=(AB→C, BC→A, BC→D, C→D)
(AB)+=ABCD (D принадлежит замыканию Þ AB→DÎ(G-AB→D)+ Þ эту зависимость можно исключить, она может быть выведена из меньшего числа).
G=(AB→C, BC→A, BC→D, C→D).
2) AB→C, G-AB→C=(BC→A, BC→D, C→D). Можем ли вывести эту зависимость из меньшего числа.
(AB)+=AB, AB→CÏ(G-AB→C)+
3)
BC→A,
G-BC→A= (AB→C, BC→D, C→D)
(BC)+=BCD – A не вошло Þ BC→A нельзя вывести Þ BC→AÏ(G-BC→A)+
4)
BC→D,
G-BC→D=(AB→C, BC→D, C→D).
(BC)+ = BCAD Þ BC→DÎ(G-BC→D)+, т.е. мы эту зависимость можем исключить. G= (AB→C, BC→A, C→D).
5) Рассмотрим C→D. Можно ли эту зависимость вывести из меньшего числа.
C→D, G-C→D=(AB→D, BC→A).
C+=C ÞC→DÏ(G-C→D)+.
1)
G=(AB→C,
BC→A, C→D)*
AB→C
a.
A→C,
A+=A ÞA→CÏG+
b.
B→C, B+=B Þ B→C ÏG+
2) BC→A. Таким же образом можно убедиться, что
B→AÏG+
C→AÏG+
Таким образом, * - минимальное покрытие и рассмотренный алгоритм – основа построения хорошей схемы БД.
Лекция 9
Свойства «хорошей» схемы БД
Схема БД называется «хорошей», если она обладает следующими свойствами:
1. Свойством соединения без потерь.
2. Свойством сохранения зависимости.
3. Свойством нормализации схем отношений схемы БД.
Примечание: последнее свойство обеспечивает отсутствие аномалий: избыточности, потенциальной противоречивости, аномалии включения записи, аномалии удаления (более подробно см. предыдущие лекции).
Свойство соединения без потерь
Определение свойства соединения без потерь
Пусть ![]() – схема БД (т.е.
– схема БД (т.е. ![]() , где A – универсальная схема отношения).
Схема БД обладает свойством соединения без потерь, если для любого экземпляра
отношения r универсальной
схемы отношений A выполняется
следующее равенство:
, где A – универсальная схема отношения).
Схема БД обладает свойством соединения без потерь, если для любого экземпляра
отношения r универсальной
схемы отношений A выполняется
следующее равенство:
![]() ,
,
где ![]() – проекция отношения r на множество атрибутов Ri (определение проекции дано в предыдущей лекции),
– проекция отношения r на множество атрибутов Ri (определение проекции дано в предыдущей лекции),
![]() – операция
естественного соединения.
– операция
естественного соединения.
Пример схемы БД, не обладающей свойством соединения без потерь.
Пусть ![]() – универсальная схема
отношения,
– универсальная схема
отношения, ![]() – схема БД, а
– схема БД, а ![]() – функциональная
зависимость.
– функциональная
зависимость.
Для доказательства утверждения, что схема БД не обладает свойством соединения без потерь, достаточно привести пример экземпляра отношения r, который не удовлетворял бы определению свойства соединения без потерь.
Пусть 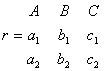 ,
,
тогда
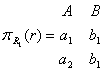 ;
; 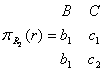 ;
;
 .
.
Пример схемы БД, обладающей свойством соединения без потерь.
Пусть ![]() – универсальная схема
отношения,
– универсальная схема
отношения, ![]() – схема БД, а
– схема БД, а ![]() – функциональная
зависимость.
– функциональная
зависимость.
Покажем, в пику предыдущему примеру, что для следующего экземпляра отношения выполняется свойство соединения без потерь:
;
; 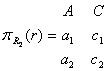 ;
;
 .
.
Теорема: пусть ![]() – схема БД, а F – множество функциональных зависимостей на универсальной
схеме отношения.
– схема БД, а F – множество функциональных зависимостей на универсальной
схеме отношения.
ρ обладает свойством соединения без потерь тогда и только тогда, когда справедлива хотя бы одна из следующих функциональных зависимостей:
1) ![]() ;
;
2) ![]() .
.
(Теорема без доказательства.)
Покажем, что в предыдущем примере схема БД ρ обладает свойством соединения без потерь.
![]() ;
;
![]() ;
;
![]() (
(![]() ), т.к.
), т.к. ![]() из F (по условию).
из F (по условию).
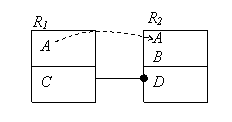
Следствие из теоремы: пусть R1 и R2 – две сущности инфологической схемы БД, которые связаны между собой.
Схема БД ![]() обладает свойством
соединения без потерь, если общие атрибуты R1 и R2 содержат ключ одной из этих сущностей.
обладает свойством
соединения без потерь, если общие атрибуты R1 и R2 содержат ключ одной из этих сущностей.
Пример:
Обладает ли ![]() свойством соединения
без потерь?
свойством соединения
без потерь?
Воспользуемся теоремой:
![]() ;
;
![]() .
.
![]() , т.к. имеет место
, т.к. имеет место ![]() (т.к. A – ключ R1).
(т.к. A – ключ R1).
Пакет ERWin позволяет строить схемы БД, обладающие свойством соединения без потерь, т.к. при определении связей между сущностями ключ родительской сущности наследуется в атрибуты дочерней сущности.
Если связь между сущностями в последнем примере была бы неидентифицирующая, все было бы то же самое.
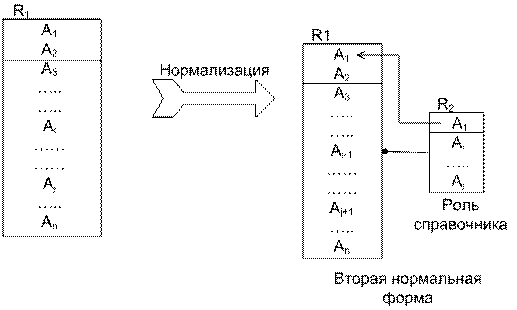
Свойство сохранения зависимости
Определение проекции множества функциональных зависимостей F на схему отношения Ri.
Пусть ![]() – схема БД, F – исходное множество функциональных зависимостей.
– схема БД, F – исходное множество функциональных зависимостей.
Проекцией
F на Ri
называется множество функциональных зависимостей ![]() таких, что имеет место
следующее включение:
таких, что имеет место
следующее включение: ![]() .
.
Проекция F на Ri
обозначается: ![]() .
.
Определение свойства сохранения зависимости
Схема БД ρ обладает свойством сохранения зависимости, если справедливо следующее равенство:
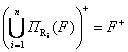 .
.
Данное выражение читается следующим образом:
1) Берется ![]() .
.
2) Полученные функциональные зависимости объединяются.
3) Для этих зависимостей строится замыкание (применяются аксиомы Армстронга).
4) Полученное множество функциональных зависимостей сравнивается с F+.
Пример схемы БД, не обладающей свойством сохранения зависимости.
Пусть ![]() – универсальная схема
отношения,
– универсальная схема
отношения, ![]() – схема БД, а
– схема БД, а ![]() – функциональная
зависимость.
– функциональная
зависимость.
Доказать, что ρ не обладает свойством сохранения зависимости.
![]() ;
;
![]() .
.
Найдем такую функциональную зависимость, которая принадлежит F+, но не принадлежит левой части выражения в определении свойства сохранения зависимости. И тем самым докажем, что ρ не обладает свойством соединения без потерь.
В качестве такой зависимости имеем:
![]() (по определению). (**)
(по определению). (**)
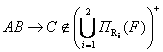 . (*)
. (*)
Для
доказательства последнего утверждения требуется построить ![]() на объединенном
множестве функциональных зависимостей и проверить
на объединенном
множестве функциональных зависимостей и проверить ![]() ?
?
![]() , но
, но ![]() .
.
Это доказывает утверждение (*).
(*) и (**)
доказывают утверждение задачи (что ρ
не обладает свойством сохранения зависимости), т.е.  .
.
Пример схемы БД, обладающей свойством сохранения зависимости.
Пусть ![]() – универсальная схема
отношения,
– универсальная схема
отношения, ![]() – схема БД, а
– схема БД, а ![]() – функциональная
зависимость.
– функциональная
зависимость.
Доказать, что ρ обладает свойством сохранения зависимости.
![]() – все зависимости,
полученные из F с помощью
аксиом Армстронга.
– все зависимости,
полученные из F с помощью
аксиом Армстронга.
Т.о. равенство доказано и данная схема БД обладает свойством сохранения зависимости.
Свойство нормализации схем отношений
Определение ключа
Пусть ![]() – некоторая схема
отношения, F – множество функциональных
зависимостей на этой схеме.
– некоторая схема
отношения, F – множество функциональных
зависимостей на этой схеме.
Тогда множество
атрибутов ![]() называется ключом
схемы отношения R, если выполняются следующие
условия:
называется ключом
схемы отношения R, если выполняются следующие
условия:
1) ![]() .
.
2) ![]() .
.
Т.е. ключ содержит в себе минимальное число атрибутов, обладающих свойством 1.
Из определения следует, что ключ в таблице всегда уникален (иначе это привело бы к тому, что таблица содержала бы крайней мере две одинаковых записи).
Лекция 10
Алгоритм
построения ключа (основывается на определении ключа)
1.
![]() ,
, ![]() – ключ на 0 шаге.
– ключ на 0 шаге.
2.
ДЛЯ по числу атрибутов в ![]() ,
, ![]()
ЕСЛИ ![]() , то
, то ![]() ,
, ![]() ,
, ![]() , выйти из цикла
, выйти из цикла
КОНЕЦ ДЛЯ
3.
ЕСЛИ ![]() – возросло, то перейти
к п. 2 алгоритма
– возросло, то перейти
к п. 2 алгоритма
ИНАЧЕ ![]() – ключ схемы отношения
– ключ схемы отношения
![]() .
.
Примечание: Алгоритм позволяет простроить один ключ. В
общем случае ключей в схеме отношения может быть несколько.
Определение 1.
Если какой либо атрибут А входит в состав какого-либо ключа схемы
отношения, то он называется первичным.
Определение 2.
Если атрибут А не входит ни в какой ключ схемы отношения, то он
называется не первичным.
Пример
построения ключа
Дано:
![]() – универсальная схема отношения;
– универсальная схема отношения;
![]() – функциональные
зависимости.
– функциональные
зависимости.
Задача:
Х
– ключ R?
Решение:
1.
![]() ,
, ![]()
2.
![]() ,
, ![]() ,
, ![]() ,
, ![]()
3.
![]() – возросло
– возросло
2.
![]()
![]()
![]() ,
, ![]() ,
, ![]() ,
, ![]()
3.
![]() – возросло
– возросло
2.
![]()
![]()
3.
![]() – не возросло,
– не возросло, ![]() – ключ.
– ключ.
Примечание:
В
данном варианте – это не единственный ключ (AB – тоже ключ). Всё зависит от последовательности
просмотра атрибутов.
![]() – тоже ключ;
– тоже ключ;
ABC – первичные атрибуты;
D – не
первичный атрибут.
Определение 3НФ (3-я нормальная форма).
Схема отношения R находится в 3НФ, если не
существует ключа X, множества ![]() , и не первичного атрибута H (
, и не первичного атрибута H (![]() ) для которых выполнялись бы следующие условия:
) для которых выполнялись бы следующие условия:
1. ![]()
2. ![]()
3. ![]()
Примечание: Из определения следует, что если можно подобрать X, Y и H для которых выполняются условия 1–3, то схема отношения не находится в 3НФ.
Пример
доказательства, что схема отношения не
находится в 3НФ
Дано:
Используя определение 3НФ доказать, что схема отношения не находится в 3НФ.
![]() – универсальная схема
отношения;
– универсальная схема
отношения;
![]() – функциональные
зависимости.
– функциональные
зависимости.
Задача:
Доказать что R не находится в 3НФ.
Решение:
- Определим ключ.
1.
![]() ,
, ![]()
2.
![]()
![]() ,
, ![]() ,
, ![]() ,
, ![]()
3.
![]() – возросло
– возросло
2.
![]()
![]()
![]() ,
, ![]() ,
, ![]() ,
, ![]()
3.
![]() – возросло
– возросло
2.
![]()
![]()
3.
![]() – не возросло,
– не возросло, ![]() – ключ схемы
отношения.
– ключ схемы
отношения.
Примечание: Можно показать, что он единственный.
- Выбираем X, Y,
H.
![]()
![]()
![]() – не первичный атрибут.
– не первичный атрибут.
- Проверяем условия 1–3, которые указаны в определении 3НФ.
1. ![]() , так как
, так как ![]() (первая аксиома
рефлексивности Армстронга);
(первая аксиома
рефлексивности Армстронга);
2. ![]() , так как
, так как ![]() (по условию
задачи);
(по условию
задачи);
3. ![]() , так как
, так как ![]() (для
доказательства последнего утверждения построим замыкание левой части (А):
(для
доказательства последнего утверждения построим замыкание левой части (А):
![]()
![]() , поэтому
, поэтому ![]() .
.
- Таким образом удалось построить тройку X, Y, H, для которой выполнялись бы условия 1–3 из определения 3НФ.
Поэтому R не находится в 3НФ и обладает всеми аномалиями.
Пример
доказательства, что схема отношения
находится в 3НФ
Дано:
Используя определение 3НФ доказать, что схема отношения находится в 3НФ.
![]() – универсальная схема
отношения;
– универсальная схема
отношения;
![]() – функциональные
зависимости;
– функциональные
зависимости;
![]() – схема БД.
– схема БД.
Задача:
Доказать что R1, R2 находятся в 3НФ.
Решение:
а) ![]() – ключ, так как
– ключ, так как ![]() по условию задачи;
по условию задачи;
б) подберём Y для
которого ![]() ,
, ![]()
![]() (
(![]() );
);
в) Здесь нельзя подобрать не первичный атрибут H, который ![]() (единственный не
первичный атрибут – B, но
(единственный не
первичный атрибут – B, но ![]() ).
).
Мы не сумели подобрать X, Y, H для которых были бы справедливы условия 1–3 из определения 3НФ, следовательно, по определению, R1 находится в 3НФ.
1) ![]() – ключ
– ключ
2) найдём Y для
которого ![]() ,
, ![]()
Легко можно убедиться, что таким условиями удовлетворяют следующие Y-ки:
а) A
б) C
в) D
г) AD
д) CD
3) Попытаемся подобрать не первичный атрибут H, для
которого ![]() ,
, ![]() .
.
Единственным претендентом является D, так как AC – ключ, D – не первичный.
а) ![]() , но
, но ![]() , потому что
, потому что ![]() ,
, ![]() ,
, ![]() (D не входит в AB)
(D не входит в AB)
б) ![]() , но
, но ![]() , потому что
, потому что ![]() ,
, ![]() ,
, ![]()
в-д) не проходят, так
как здесь не первичный атрибут (D) ![]() .
.
Методом логических исключений мы пришли к выводу, что здесь нельзя подобрать X, Y, H для которых были бы справедливы условия 1–3 из определения 3НФ, следовательно, по определению, R1 находится в 3НФ.
Поэтому вывод – R2 находится в 3НФ.
Алгоритм построения «хорошей» схемы БД
Дано:
![]() – универсальная схема
отношения;
– универсальная схема
отношения;
F – исходное множество функциональных зависимостей на R.
Задача:
Построить «хорошую» схему БД. ![]() – ?
– ?
Решение:
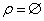
- Определить минимальное покрытие G для функциональных зависимостей F (см. предыдущие лекции).
- Каждую функциональную зависимость V вида
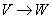 из G заменить на VW (объединить атрибуты левой и правой частей).
Получившееся множество схем отношений обозначить Q.
из G заменить на VW (объединить атрибуты левой и правой частей).
Получившееся множество схем отношений обозначить Q. - Если
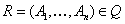 , то добавить в
, то добавить в 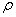 схему отношения
схему отношения 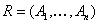 и выйти из
алгоритма, ( – «хорошая» схема БД).
и выйти из
алгоритма, ( – «хорошая» схема БД).
Иначе перейти к пункту 5.
- Добавить в в качестве схем
отношений все те одиночные атрибуты, которые не вошли ни в одну из схем из
Q.
- Добавить в все схемы
отношений из Q.
Примечание: после выполнения пунктов алгоритма 1-6 схема БД обладает Свойством Сохранения Зависимостей, и каждая её схема отношения находится в 3НФ.
- Если ни одна из схем отношений в не содержит в
себе ключ для универсальной схемы отношения R, то
добавить в какой-нибудь ключ
для R в качестве схемы отношения.
Примечание: после выполнения всех 7 пунктов алгоритма схема БД обладает всеми свойствами «хорошей» схемы БД:
1) Свойство Соединения Без Потерь;
2) Свойство Сохранения Зависимостей;
3)
Каждая схема отношения в ![]() находится в 3НФ.
находится в 3НФ.
7-е условие слишком жесткое (надо найти ключ для универсальной схемы отношения – а в ней бывают сотни атрибутов).
Примечание: 7-ой пункт предполагает, что, в принципе, при
разработке таблиц в БД, будут соединены все таблицы из ![]() , но на практике такого не бывает, поэтому его можно
ослабить:
, но на практике такого не бывает, поэтому его можно
ослабить:
7.
Если в запросах к БД ![]() соединяет не все схемы
отношений из
соединяет не все схемы
отношений из ![]() , а только из подмножества
, а только из подмножества ![]() ,
, ![]() , …,
, …, ![]() , то в
, то в ![]() можно добавить ключи
для Q1, Q2, …, Qk в качестве новых схем отношений. (Если,
конечно, эти ключи не содержатся уже ни в одной из схем отношения из
можно добавить ключи
для Q1, Q2, …, Qk в качестве новых схем отношений. (Если,
конечно, эти ключи не содержатся уже ни в одной из схем отношения из ![]() ).
).
Лекция 11
Пример построения
хорошей схемы БД
(в этом же стиле первая задача курсовой работы).
Пусть R=(имя, адрес, товар, цена)=(А,В,С,D)
F=(A→B, BC→D, AC→D, B→A)
Задача:
Построить хорошую схему БД – ρ.
Воспользуемся алгоритмом:
- ρ=Ø
- Воспользуемся алгоритмом построения минимального покрытия
G=(A→B, BC→D, AC→D, B→A)
2.2.1.1
A→B, G – A→B=(BC→D, AC→D, B→A)
(A)+=A, A→B![]() (G – A→B)+
(G – A→B)+
2.2.1.2
BC→D, G – BC→D=(A→B, AC→D, B→A)
(BC)+=BCAD è BC→D![]() (G – BC→D)+ è Данную
функциональную зависимость исключаем из G
(G – BC→D)+ è Данную
функциональную зависимость исключаем из G
G=(A→B, AC→D, B→A)
2.2.1.3
AC→D, G – AC→D=(A→B, B→A)
(AC)+=ACB è AC→D![]() (G – AC→D)+
(G – AC→D)+
2.2.1.4
B→A, G – B→A=(A→B, AC→D)
(B)+=B, B→A![]() (G – B→A)+ è
(G – B→A)+ è
G=(A→B, AC→D,
B→A)
2.2.2
В дальнейшем замыкания множества атрибутов
рассматривается для G
2.2.2.1
AC→D
a) A→D
(A)+=AB, A→D![]() (G)+ - (Если
это верно, то можно заменить AC→D на A→D. Док-во:AC→A, A→D è AC→D, тогда AC→D можно заменить на A→D )
(G)+ - (Если
это верно, то можно заменить AC→D на A→D. Док-во:AC→A, A→D è AC→D, тогда AC→D можно заменить на A→D )
b)
C→D
(C)+=C , C→D
![]() (G)+
(G)+
G=(A→B, AC→D, B→A) – минимальное покрытие.
- Q=(AB, ACD, BA) = (AB, ACD)
- Нужно убедиться, что R
 Q. Так оно
и есть: R = ABCD Q = (AB, ACD).
Q. Так оно
и есть: R = ABCD Q = (AB, ACD). - ---
- ρ = (AB, ACD).
- Определим ключ для R
7.1. i:=0; x0=BACD (изменение
в последовательности символов связано с известным заранее результатом )
7.2.
(ACD)+ = ACDB = R, x1 = ACD, i++;
7.3.
i==1;
7.2.
(CD)+ = CD ≠ R
(AD)+ = ADB
≠ R
(AC)+ =
ACBD = R, x2=AC, i++;
7.3.
i==2;
7.2. (C)+ = C ≠ R;
(A)+ = A ≠ R;
7.3. i==2;
x = x2 =
AC – ключ R.
AC![]() ACD в ρ = (AB, ACD) è В ρ ничего
не надо добавлять, и поэтому ρ = (AB, ACD) – хорошая схема БД.
ACD в ρ = (AB, ACD) è В ρ ничего
не надо добавлять, и поэтому ρ = (AB, ACD) – хорошая схема БД.
Первое задание курсовой работы.
Дана универсальная схема отношений:
R =( A – читаемый курс, В – преподаватель, С – час начала занятия, D – аудитория, E – студент, T – оценка по курсу)
Задано множество физических зависимостей:
F = (CD→B – в аудитории одновременно может быть только один
преподаватель,
AC→D – каждый курс одновременно может читаться только в одной
аудитории,
CE→A – каждый студент одновременно может слушать только один
курс,
A→B – каждый курс ведет только один преподаватель,
CD→A – в аудитории одновременно может читаться только один курс,
CB→D – преподаватель одновременно может находиться только в
одной аудитории,
AE→T – по каждому курсу каждый студент имеет только одну оценку,
CE→D – студент в один момент времени может находиться только в одной аудитории.
)
Задача: Построить хорошую базу данных (ρ).
Примечание:
Приложение к пункту 7 не учитывать.
Преимущества и недостатки построения хорошей схемы БД.
Преимущества «+»
- Алгоритм определяет стандартную процедуру построения схемы БД, обладает свойствами соединения без потерь, сохранения зависимостей и нормализации отношений.
- Можно использовать для доказательства, что схема БД оптимальна. (может понадобиться на дипломе)
Недостатки «-»
- Очень сложно определить все множество физических зависимостей предметной области (Алгоритм критичен к набору физических зависимостей → неустойчив)
- При увеличении числа физических зависимостей сложность вычислений резко возрастает.
- Синтез хорошей схемы БД, как правило, приводит к увеличению схем отношений в схемах БД. Чтобы объединить данные в схемах отношений необходимо в операторах SQL использовать соединение таблиц, а это приводит к увеличению времени выполнения запроса.
Указанные недостатки сдерживают применение рассмотренного метода на практике.
Но существует практические приемы нормализации, которые позволяют обойти эти недостатки.
Практические приемы нормализации схем отношения.
1) Приведение схемы отношения к первой нормальной форме.
Схема отношения находится в первой нормальной форме, если она не содержит вектор или других схем отношения.
2) Приведение схемы отношения ко второй нормальной форме.
Схема отношения находится во
второй нормальной форме, если не существует ключа Х, множества атрибутов Y![]() X * и не
первичного атрибута H
X * и не
первичного атрибута H![]() Y, для которых были бы справедливы следующие
свойства.
Y, для которых были бы справедливы следующие
свойства.
·
X→Y![]() F+
F+
·
Y→H![]() F+
F+
·
Y→X![]() F+
F+
(Это определение очень напоминает определение третьей нормальной формы, отличие только в *)
X=A1A2
Y=A1 ![]() X(A1→Ai…Aj)
X(A1→Ai…Aj)
H – один из
атрибутов Ai…Aj
Так как получилось подобрать X, Y, H è R1 – не находится во второй нормальной форме.
3) Приведение схемы отношения к третьей нормальной форме.
X=A – ключ.
Y=A2 ![]() R1(A2→Ai…Aj)
R1(A2→Ai…Aj)
H=Ai…Aj
Так как подобрали X, Y, H è R1 ≠ Третьей нормальной форме.
Лекция 12
X=A1A5 – схема отношений R1 (A5 – кат. вектор)
Y=A1(A1→A2A3A4)
H![]() (A2,A3,A4)
(A2,A3,A4)
A3→A4
Не в 1,2,3 НФ.
Задача нормализовать данную таблицу.
Каждая схема будет в 3НФ, если каждый сотрудник занимает 1 должность на предприятии. Если это не так, то в исходной таблицу R1 входит другая схема, состоящая из других атрибутов.
В этом случае схему БД необходимо преобразовать, т.к. R1 не находится в 1 НФ.
Оптимизации (“на пальцах”)
- Без потерь – правильные SQL запросы
- A→B аномалия отсутствие
противоречивости, включения
- потенциальной избыточности.
На этом мы завершим теорию “Марксизма и Ленинизма” (Дословно;-))
Методы индексации данных в реляционных СУБД
Индекс – это некоторая структура, обеспечивающая быстрый поиск данных в БД.
Различают следующие типы Индексов:
- Хэш – индекс
- B – индекс
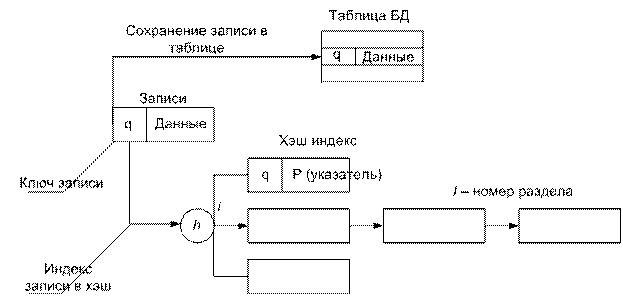
Включения записи в БД
- Запись сохраняется в таблице БД
- Выполняется с помощью хэш-функции, номер раздела по ключу
h(q)=i – номер хэш индекса
И в этот раздел (i) помещается запись (q,P), где это указатель на индекс БД.
q→h(q)=i→
Чтение i-ого раздела
хэш-индекса→
Поиск записи (q, P) в i-ом разделе по ключу q→
Чтение блока из таблицы БД по указателю P→
Поиск в блоке требуемой записи.
Для того, чтобы прочитать требуемое №2 обращение к диску.
B – индексы.
Сторятся для следующих атрибутов:
- Для первичного ключа. (Primary Key)
- Для альтернативного ключа. (AK – другой уникальный ключ)
- Для произвольного набора атрибутов. (IK – инвертированные списки)
Для первых двух случаев, значение ключей в индексе не могут повторяться (всегда уникален)
В 3 случае, значение индексируемых атрибутов могут повторяться в индексе (Фамилия)
Какие существуют
Различают следующие типы B- индексов.
- Обычные B-индексы (B-деревья)
- Битовые индексы (Bit Mappend)
- Реверсивыне индексы (Reverse Key Index)
- Индекс Таблицы (Индекс Таблицы)
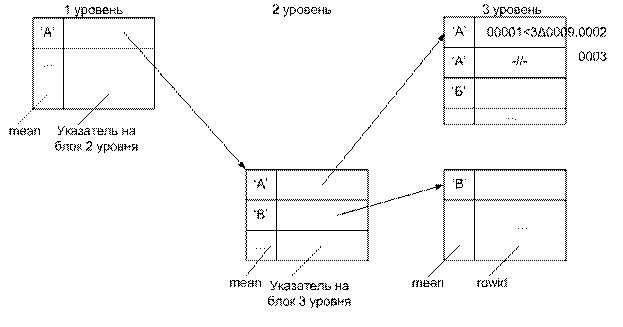
Структура
Обычный индекс представляет собой совокупность иерархически-связанных блоков, а када запись блока листового уровня имеет следующую структуру:
<Значение индекс. Атрибута (mean) идентификатор записи
табл. БД (rowid)>
При переполнении таблицы делятся пополам – B – деревья.
Если нужно ‘B’ →
- читаю ‘A’ – 1 уровень. ≠Г
- читаю, например, ‘Г’ дальше в 1 уровне ≠B и лексикографически это больше, чем ‘B’→
- Возврящаюсь назад к ‘А’ и иду на 2 уровень
- Читаю на II уровне ‘A’ ≠’B’
- ‘B’=’B’ → конец.
(q, rowid)
/
Значение инд. Атрибута
Все записи блоков любого уровня упорядочены по значению главного атрибута. Если места в блоке листового уровня, то запись выполняетс в этот блок.
Если мест нет, то блок листового уровня расширяется на 2.
Ниняя часть старого блока переписывается в нижнюю часть нового блока и в блоке более верхнего уровня создается mean – указатель.
Предположим необходимо найти записи со значением индексного атрибута = q.
Раз просматриватся индекс, начиная с 1 уровня и на каждом уровне q<= mean из указателя читается информация следующего уровня, просматривается и т. д.
Когда будет считан блок листового уровня q=mean.
После этого определяется rowid и по этим идентификаторам выполняется чтение или запись.
ROWID
00001<3aA идентификатор файла БД.
0007 – номер блока.
0002 – номер записи.
Данный пример указывает, что 0002, 0003 имеет значение индекс атрибута с А.
Определение числа уровней в обычном
Число уровней является переменным и определяется из того, что число блоков в индексе на 1 уровне всегда =1.
- V – число записей в таблице БД.
- К – маx число записей в 1-одном блоке индекса
- L- число уровней в индексе
Все переполнены уровни, сколько уровней?
V/K – количество блоков
листового уровня.
V/K![]() - число блоков индекса на L-1 уровне.
- число блоков индекса на L-1 уровне.
.
.
V/K![]() =1 – число блоков в индексе на 1 уровне.
=1 – число блоков в индексе на 1 уровне.
L = log![]() V
V
Преимущества и недостатки обычных B – деревьев
Преимущества:
- При обновлении записи в таблице БД, блокируется только эта запись.
- Очень хорошо изучены
- Эффективные алгоритмы их реализации
Недостатки:
- Достаточно большой объем внешней памяти, занимаемой индексом
Рассчитаем объем, занимаемый листовыми блоками обычного B-индекса.
- V – число записей в таблице БД.
- I – мощность индекс. атрибута (число различных значений)
- L
 - длина индекс. атриб. В схеме таблицы
- длина индекс. атриб. В схеме таблицы - L
 - длина идентификатора записи (rowid)
- длина идентификатора записи (rowid)
Предположим, что все блоки листового уровня заполнены.
Тогда объем этих блоков Q=V(L![]() + L
+ L![]() )
)
Лекция 13
Недостатки обычных В-деревьев:
- большое время выполнения операций над списками с индексированными записями
Пример
Пусть условие поиска в БД имеет следующий вид:
q = ‘A’ AND
s = ‘B’
|
|
q |
|
s |
|
|
|
|
|
|
|
|
|
A |
|
B |
|
|
|
|
|
|
|
|
|
|
|
|
|
Индексы строятся для атрибутов какой-либо 1 таблицы. Предположим, что атрибуты q и s индексированы. Поиск требуемых записей в индексе осуществляется следующим образом:
1) используя индекс для q система идентификаторы записей, у которых q=’A’.
q=’A’ –
2) используя индекс для s система идентификаторы записей, у которых s=’B’.
s=’b’ – {rowid}s=’B’
3) для получения результирующего списка результатов система строит пересечение списков
{rowid}q=’A’ ![]() {rowid}s=’B’
{rowid}s=’B’
4) Используя полученные идентификаторы записи читаются из БД
При выполнении 3 пункта СУБД организует вложенные циклы для просмотра и определения пересечений списков. На это тратится достаточно много времени.
Примечание.
Иногда чтобы улучшить время выполнения запроса поиск записей осуществляется по 1 индексированному атрибуту, остальные условия проверяются программно.
Битовые
индексы
Структура битового индекса такая же, как и для рассмотренного выше обычного В-индекса. Они отличаются структурой записи блока листового уровня.
Битовый индекс имеет структуру записи блока листового уровня:
< значение индексируемого атрибута (mean), - их может быть несколько
начальный идентификатор записи (start_rowid),
конечный идентификатор записи (end_rowid),
сегмент двоичной карты (bitmap_segment)>
Пример записи блока листового уровня, построенного для атрибута q.
q
|
‘A’ |
13 |
20 |
01100101 |
|
mean |
start_rowid |
end_rowid |
bitmap_segment |
Здесь идентификатор записи записаны в упрощенном виде, полный вид см. выше.
В битовой маске каждый бит соответствует записи из указанного интервала. Битовая маска означает, что 14,15, 18 и 20 записи БД имеют значение атрибута q = ‘A’.
Преимущества битовых индексов
1) Битовый индекс занимает меньший объем памяти, чем обычное В-дерево.
Дадим оценку объема памяти, занимаемой блоками листового уровня битового индекса.
V – число записей в таблице БД
Lq – длина индексируемого атрибута
Lr – длина идентификатора записи (rowid)
Lb – длина битового сегмента двоичной карты
Требуемый объем вычисляется по формуле:
![]() , где
, где ![]() = длина записи блока
листового уровня битового индекса.
Q << объема
памяти блоков листового уровня для В-дерева.
= длина записи блока
листового уровня битового индекса.
Q << объема
памяти блоков листового уровня для В-дерева.
![]() - примерное число
записей в блоках листового уровня
- примерное число
записей в блоках листового уровня
Каждая запись листового уровня описывает примерно 8Lb записей в таблице БД.
2) Быстрое выполнение операций с сегментами двоичной карты
Задано то же условие поиска, оценим качественно время его выполнения
Предположим, что атрибуты q и s индексированы с помощью битовых индексов.
|
|
q |
|
s |
|
|
|
|
|
|
|
|
|
A |
|
B |
|
|
|
|
|
|
|
|
|
|
|
|
|
q
|
‘A’ |
13 |
20 |
bitmap_segment |
s
|
‘B’ |
13 |
20 |
bitmap_segment |
Поиск записей, удовлетворяющих условиям выполняется в следующей последовательности:
1) Выделяется bitmap_segment1. (Индексы по s читаются в битовый сегмент bitmap_segment1)
2) Выделяется bitmap_segment2 (Индексы по s читаются в битовый сегмент bitmap_segment2)
3) Определяется результирующий битовый сегмент двоичной карты
bitmap_segment1 ![]() bitmap_segment2
= bitmap_segment3
bitmap_segment2
= bitmap_segment3
4) Определяется список идентификаторов записей, удовлетворяющих условиям. На интервал (13, 20) накладывается заданная маска (13,20) {bitmap_segment}3
При выполнении 3 операции выполняется логическое пересечение битовых массивов, это можно выполнить 1 ассемблерной командой (системе не требуется выполнять вложенных циклов)
Недостаток битовых индексов
При обновлении только 1 записи блокируются все записи таблицы БД, которые входят в сегментную карту.
Например, если обновляется только 14 запись, блокируются записи с 13 по 20.
Реверсивный индекс
Запись блока листового уровня имеет следующий вид:
< реверсивное значение индексируемого атрибута (mean),
идентификатор записи (rowid)>
Примеры записей блока листового уровня:
|
приток -> |
котирп |
01 |
|
пример -> |
ремирп |
02 |
В лингвистике показывается, что последние буквы слова более равномерно распределены по алфавиту, чем первые буквы слова.
Это свойство реверсивных индексов используется в больших кластерных системах для равномерного распределения записей индекса по серверам кластера.
предположим, что необходимо создать индекс для русских слов (для определенной предметной области)
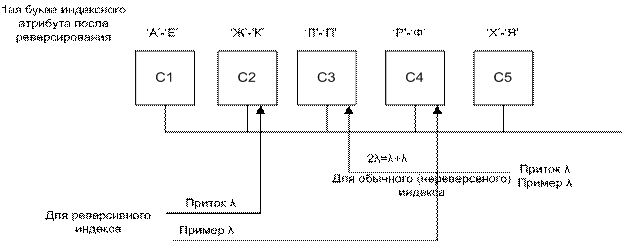
В данном примере нагрузка на сервер снижается в 2 раза.
Индекс-таблица
По своей структуре индекс-таблицы являются В-деревьями, но в блоке листового уровня вместо идентификатора записи хранятся атрибуты этой записи.
|
код |
остальные атрибуты записи |
mean
Преимущество: из индекса читается сама запись (это сокращает врем доступа к данным)
Недостаток: резко осложняется процедура ведения индекса (индекс и БД едины)
После оптимизации схемы БД, после выбора индексируемых атрибутов, их характеристик выполняется генерация DDL сценария с помощью CASE-средств (ErWin, например). В этом сценарии в основном сохраняются операторы создания различных объектов (таблицы, хранимые процедуры и т.д.) После этого файл с DDL-сценарием прогоняется на сервере БД с помощью соответствующих утилит (например, в Oracle команда @ в утилите SQL+). В результате создаются требуемые объекты, к которым затем можно обращаться с помощью языка манипулирования данными (в основном SQL).
Специальная
обработка текстовых полей (атрибутов) БД
Целью дальнейшего рассмотрения является следующее: показать, как с помощью ТФЯ можно строить небольшие трансляторы.
Лекция 14
Элементы теории
формальных языков
Определения
- Алфавит – непустое конечное множество символов.
- Цепочка
– конечная последовательность символов алфавита.
- Конкатенация
двух цепочек x и y - это цепочка z, которая получается
путём приписывания в конец цепочки x символов цепочки y.
- Произведение
двух множеств цепочек x и y - это
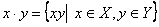 .
. - Степень
алфавита А определяется следующим образом:
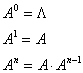
Здесь: Λ- пустой символ, А – сам алфавит, _ -произведение двух множеств цепочек (смотри п.4). - Усечённая
итерация алфавита А определяется следующим образом:
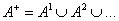
- Итерация
алфавита А определяется следующим образом:
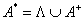 , где Λ –пустой символ.
, где Λ –пустой символ.
Пример построения итерации алфавита А
Задание
А=(a,b) – алфавит
Определить А*.
Решение
А*= (Λ, a, b, aa, ab, ba, bb, aaa, aab, aba, abb, baa, bab, bba, bbb…)
A1 A2 A3
Определение грамматики
Правило – выражение вида
<U>::= u, где U – символ
алфавита, u – цепочка символов алфавита.
::= читается как «есть по определению».
Грамматикой G(z) называется непустое конечное множество правил, где символ <z> должен встречаться в левой части, по крайней мере, одного из правил. Этот символ называется начальным символом.
Все символы, которые встречаются и в левой, и в правой частях грамматики, образуют словарь V.
Символы, которые встречаются в левых частях правил, называются нетерминальными. Их множество обозначается N.
Все остальные символы словаря, не входящие в N, называются терминальными. Их множество обозначается T.
![]()
Множество правил с одинаковой левой частью, например,
<U>::=x
<U>::=y
…
<U>::=z
сокращенно записывают <U>::=x|y|…|z.
Читается «Символ U есть по определению либо x, либо y, либо …, либо z».
Пример грамматики
Задание
Написать грамматику натурального числа (0 не входит в множество натуральных чисел).
<Z>::=<чс> , здесь <чс> - нетерминальный символ «число» (1)
<чс>::=<цифра>|<чс>|<цифра1> (2)
<цифра>::=1|2|…|9 (3)
<цифра1>::=0|<цифра> (4)
N={<Z>, <чс>, <цифра>, <цифра1>}
T={0,1,…,9}
![]()
Язык, описываемый грамматикой
1. Пусть G(<z>) – грамматика. Говорят,
что цепочка v непосредственно порождает цепочку w, если можно записать следующее
равенство
v=x<U>y, w=xuy, где
<U>::=u, a x и y –
некоторые цепочки (они могут быть пустыми).
Непосредственный вывод обозначается следующим образом ![]()
Пример построения непосредственных выводов на примере грамматики натурального числа
|
Цепочка v |
Цепочка w |
№ правила |
||||
|
x |
<U> |
y |
x |
u |
y |
|
|
|
<z> |
|
|
<чс> |
|
1 |
|
|
<чс> |
|
|
<чс><цифра1> |
|
2 |
|
|
<чс> |
<цифра1> |
|
<цифра> |
<цифра1> |
2 |
|
|
<цифра1> |
<цифра1> |
|
2 |
<цифра1> |
3 |
|
2 |
<цифра1> |
|
|
2 |
0 |
4 |
С помощью непосредственных выводов можно получать цепочки, состоящие только из терминальных символов.
2. Вывод цепочки w из цепочки v.
Говорят, что цепочка v порождает цепочку w (w выводится из v), если существует следующая последовательность
непосредственных выводов ![]()
Если v≠w, то ![]() (непосредственная выводимость)
(непосредственная выводимость)
Если v=w или
![]() , то вводят следующее обозначение
, то вводят следующее обозначение ![]()
Общее правило вывода
Для вывода w из v необходимо последовательно менять нетерминальные символы в v на правые части соответствующих правил из грамматики.
Из предыдущего примера следует, что ![]()
3. Пусть G(z) - грамматика. Цепочка x называется сентенциональной
формой, если она выводится из начального символа, то есть ![]()
![]()
4. Предложение языка – это сентенциональная форма, состоящая только из терминальных символов.
5. Язык – это множество предложений, то есть цепочек, выводимых из начального символа <z> и состоящих из терминальных символов.
![]() ,
,
где Т+ - усеченная итерация множества терминальных символов.
Синтаксические
деревья
Для любого вывода предложения языка можно построить синтаксическое дерево.
Синтаксическое дерево строится только для вывода
предложения.
На основе грамматики натуральных чисел можно построить следующий вывод.
![]()
Для этого вывода можно построить синтаксическое дерево.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Куст узла – родительский узел и множество подчинённых ему дочерних узлов.
Родительскому узлу соответствует некоторый нетерминальный символ <u> (в данном случае, <чс>).
Дочерним узлам куста соответствуют символы цепочки u, при этом должно существовать правило <U>::=u.
Дочерний узел может выступать в качестве родительского в другом кусте.
Концевые листовые узлы – узлы, не имеющие куста.
Символы листовых узлов, записанные слева направо, образуют предложение языка.
Нисходящие
распознаватели
Нисходящий распознаватель – это транслятор, который при разборе предложения языка строит синтаксическое дерево сверху вниз.
Левосторонняя и правосторонняя рекурсия
Правило имеет левостороннюю рекурсию, если оно записано следующим образом.
<U>::=…|<U>x|…
то есть в какой-либо альтернативе первый символ – это нетерминальный символ U, стоящий в левой части правил.
Правило имеет правостороннюю рекурсию, если оно записано следующим образом.
<U>::=…| x <U> |…
то есть в какой-либо альтернативе самый первый символ – это нетерминальный символ, стоящий в левой части правил.
Чтобы избежать зацикливания в нисходящих распознавателях, необходимо избавляться от левосторонней рекурсии.
Способы устранения левосторонней рекурсии
Продемонстрируем на примере грамматики арифметического выражения.
Она имеет вид:
|
<Z>::=<E> |
(1) |
|
<E>::=<T>|<E>+<T>|<E>-<T> |
(2) |
|
<T>::=<F>|<T>*<F>|<T>/<F> |
(3) |
|
<F>::=(<E>)|i |
(4) |
Здесь i – либо константа, либо переменная со знаком или без.
В этой грамматике для простоты не учитывается возведение в степень. Здесь (2) и (3) правила имеют левостороннюю рекурсию.
Существует два способа избавления от левосторонней рекурсии.
1. Замена левосторонней рекурсии на правостороннюю.
Правила (2) и (3) можно переписать следующим образом.
|
<E>::=<T>|<T>+<E>|<T>-<E> |
(2a) |
|
<T>::=<F>|<F>*<T>|<F>/<T> |
(3a) |
Правила (2а) и (3а) эквивалентны правилам (2) и(3).
2. Замена нетерминальных символов в правой части правила на символы, обозначающие «хвост».
Правила (2) и (3) можно переписать следующим образом.
|
<E>::=<T>{+<T>;
-<T>} |
(2б) |
|
<T>::=<F>{*<F>;
/<F>} |
(3б) |
Например, правило (2б) читается следующим образом «Нетерминальный символ <E> есть по определению нетерминальный символ <T>, за которым возможен «хвост», состоящий из смеси цепочек +<T> и -<T>».
Фигурными скобками обозначается «хвост».
Правила (2б) и (3б) эквивалентны правилам (2) и (3).
Лекция 15
Общие правила
(рекомендации) для разработки нисходящих распознавателей.
1. Во всех правилах грамматики избавиться от левосторонней рекурсии
( см. предыдущую лекцию)
2. Для каждого правила <U>::= u разработать программу, которая будет удовлетворять следующим требованиям:
А. Программа должна либо определить «u» (т .е. требуемые операции), либо сообщить о невозможности это сделать.
Б. Если при разборе «u» встречается нетерминальный символ <X> (u=…<X>…), то для анализа этого нетерминального символа <X> необходимо передать управление программе, связанной с правилом: <X>::=x.
В. При отрицательном ответе после анализа нетерминального символа <X> программа разбора цепочки «u» должна либо проанализировать альтернативный вариант(в цепочке «u» где-то встречается альтернатива u::= …<X>| альтернатива), либо выдать сообщение об ошибке.
Г. В начале управление должно быть передано программе :<Z>::=…, где <Z>- начальный символ.
Примечание: Таким образом, спецификацией нисходящего распознавателя являются правила грамматики, это следует из рекомендаций, перечисленных выше.
Пример нисходящего распознавателя для грамматики описывающей арифметическое выражение.
Предположим задана грамматика арифметического выражения:
- <Z>::=<E>
- <E>::=<T> |
<E> + <T> | <E> - <T>
- <T>::=<F> |
<T> * <F>| <T> / <F>
- <F>::=(<E>) | i, где I либо const, либо идентификатор.
Для разработки распознавателя арифметического выражения воспользуемся приведенными выше рекомендациями.
1) правила 2 и 3 имеют левостороннюю рекурсию => избавляемся от неё:
1. <Z>::=<E>
2.<E>::=<T> | { (+|-) <T>}
3.<T>::=<F> | {( *| /) <F>}
4.<F>::=(<E>) | i
2) каждому правилу поставим в соответствие функцию fi. Каждая из этих функций имеет следующий прототип:
int fi(char **u, double *d);
*u- указатель на текущий символ разбираемого арифметического выражения.
*d- текущее значение числа рассчитанное при вызове функции.
int – каждая функция возвращает код ошибки( 0- нет ошибки; 1- ошибка, прекратить вычисления)
Схема, поясняющая
необходимость использования двойного указателя **u для перемещения к следующему символу
арифметического выражения в вызываемой и вызывающей программах.
1)char **u:
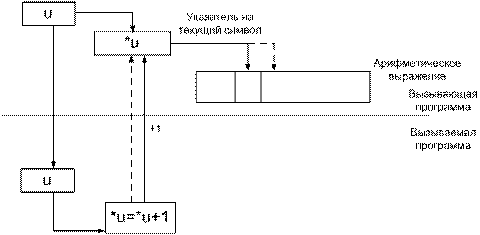
2)char *u:

Схема взаимодействия функций fi в соответствии со сформулированными правилами
(рекомендациями).
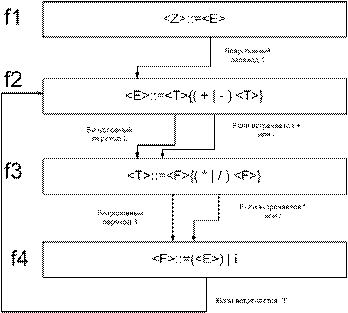
Реализация функций f1, f2, f3, f4.
Для обработки ошибки будем использовать следующий макрос:
#define
fun(a) if (a) return(1)
f1:
*u – указатель на начальный символ арифметического выражениях;
d - указатель на переменную, где будет храниться окончательное результирующее число.
int f1 (char
**u, double *d)
{
return(f2(u, d)); // реализация безусловного перехода 1
}
f2:
int f2(char
**u, double *d)
{
double d1;
fun (f3(u, d)); // реализация безусловного перехода 2
while (1) // реализация «хвоста»
{
*u+=strspn(*u, “ “); // продвинуть указатель за пробел
switch (**u)
{
case’+’:
(*u)++; // перейти за «+»
fun (f3(u, &d1)); // обращение к f3 если встречается «+»
*d+=d1;
break;
case’-’:
(*u)++; // перейти за «-»
fun (f3(u, &d1)); // обращение к f3 если встречается «-»
*d-=d1;
break;
defalt: // больше нет символов хвоста
return(0);
}
}
}
f3:
int f3(char
**u, double *d)
{
double d1;
fun (f3(u, d));
while
(1)
{
*u+=strspn(*u, “ “);
switch (**u)
{
case’*’:
(*u)++;
fun (f4(u, &d1));
*d*=d1;
break;
case’/’:
(*u)++;
fun (f4(u, &d1));
*d/=d1;
break;
defalt:
return(0);
}
}
}
f4:
int f3(char
**u, double *d)
{
*u+=strspn(*u,
“ ”);
if
(**u==’(’)
{
(*u)++;
fun (f2(u, d ));
*u+=strspn(*u,” “);
if (**u!=”)“)
return (1);
else
{
(*u)++;
return (0);
}
}
//Разбор альтернативы (вычисление i)
разбор I (const или идентификатор)
if ( ошибка)
return(1);
else
{
*d=число, полученное после разбора
return(0);
}
}
Синтаксическое дерево строится неявно. Дерево образует последовательность вызовов функций f1-f4.
Покажем, как разработанный распознаватель строит синтаксическое дерево. Пусть задано следующее арифметическое выражение:
25 + (A+B) / C*D
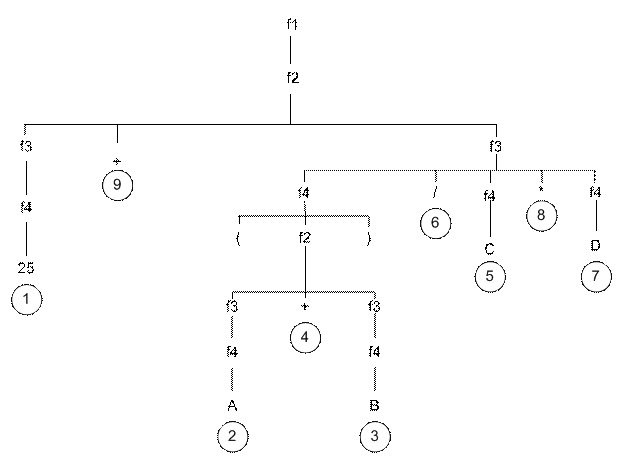
Лекция 16
Восходящие распознаватели
Восходящие распознаватели
- это транслятор, которое строит
синтаксическое дерево сверху- вниз.
Основа - дочерние узлы какого-либо куста синтаксического дерева.
Восходящие распознаватели выполняют следующую последовательность шагов:
1- Выполняют поиск основы Х
2- Выполняют поиск правила грамматики:
<U>::= х;
3- Привязывают х к нетерминальному символу <U> и таким образом строят куст
синтаксического дерева.
Алгоритм продолжается, начиная с пункта 1.
В дальнейшем восходящие распознаватели рассматривают на примере операторных грамматик.
Грамматика G(<Z>) называют операторной, если ни одно из ее правил не записано в следующем виде:
<U>::= <V> <W>, то есть никакая правая часть любого правила не содержит двух соседних нетерминальных символов.
Примеры: грамматика арифметического выражения;
Условие поиска в операторе SELECT.
Для разработки восходящего распознавателя необходимо определить следующие компоненты:
1- Отношения между операторами грамматики (операторы- терминальные символы, которые разделяют нетерминальные символы в правых частях правил команд).
2- Необходимо определить числовые функции предшествования f и g.
I.
Рассмотрим отношения между операторами:
Можно выделить 3 типа отношений между операторами:
1- отношение: r◦<s: означает оператор r непосредственно предшествует оператору S но перед оператором r вначале надо вычислить S.
Пример:
а) для арифметических выражений:
+◦<* а+в*с (+ это r; * это s)
б) для логических выражений: Или ◦< и
OR
◦<AND A=3 OR B=
2 AND
C<5
2- отношение: r◦>s Оператор r непосредственно предшествует S и перед определением S необходимо вычислить r.
Пример:
а) для арифметических выражений:
а + в - с (+ это r, - это s)
б) для логических выражений: OR ◦> OR
|
|
r |
|
s |
|
|
A=3 |
OR |
B =2 |
OR |
C <3 |
3- отношение: r◦ = s Означает, что оператор r непосредственно предшествует S; r и S необходимо в дальнейшем исключить из рассмотрения:
а) (◦= ) для арифметического выражения
|
r |
|
s |
|
( |
а |
) |
б) для логического (◦ =)
|
r |
|
s |
|
( |
а |
) |
II.
Определим функции предшествования:
Числовые функции f и g называются функциями предшествования, если они удовлетворяют условиям:
1- Отношение r◦<S эквивалентно f(r)<g(s)
2- Отношение r◦<s эквивалентно f(r) > g(s)
3- Если r◦=s эквивалентно f(r) = g(s)
Примеры отношений между операторами и функции предшествования для грамматики арифметического выражения
Пусть задана грамматика арифметического выражения:
1) <Z>::=<E>
<E>::=<T>| <E> + <T>|<E>-<T>
2)
<T> ::= <F> | <T> * <F> | <T>/<F>
<F>::=
(<E>)i
Здесь не учитывается возведение в степень, i- константа или идентификатор. Здесь операторами являются +, -, *, /, ( ).
Определим отношения
|
s
r |
+ |
- |
* |
/ |
( |
) |
‘\0’ |
|
+ |
◦> |
◦> |
◦< |
◦< |
◦< |
◦< |
◦< |
|
- |
◦> |
◦> |
◦< |
◦< |
◦< |
◦> |
◦> |
|
* |
◦> |
◦> |
◦> |
◦> |
◦< |
◦> |
◦> |
|
/ |
◦> |
◦> |
◦> |
◦> |
◦< |
◦> |
◦> |
|
( |
<◦ |
◦< |
◦< |
◦< |
◦< |
◦= |
ошибка |
|
) |
◦> |
◦> |
◦> |
◦> |
ошибка )( |
◦> |
◦> |
между операторами, сведем эти отношения в таблицу.
‘0’- конец строки
По концу строки должны выполняться операторы.
Функции
предшествования
Функций предшествования для данной грамматики может быть очень много. Ниже приведен 1 пример для функций предшествования f и g.
|
|
f |
g |
|
+ |
10 |
9 |
|
- |
10 |
9 |
|
* |
12 |
11 |
|
/ |
12 |
11 |
|
( |
8 |
13 |
|
) |
12 |
8 |
|
‘\0’ |
|
0 |
Числа для функций предшествования выбираются так, чтобы они соответствовали отношениям между операторами.
Например:
1) +◦<*
f(+)= 10 , g(*)=11
f(+) < g(*)
2) + ◦ > +
f(+) = 10, g(+)=9
f(+)=g(+)
Алгоритм
программы восходящего распознавания для любой операторной грамматики
1) Создать 2 стека: Stack1 для операторов, Stack2 для операндов.
Примерная структура Stack1:
|
s1 |
f(s1) |
g(s1) |
Адрес программы обработки оператора s1 |
|
… |
… |
… |
… |
2) Начать или продолжить разбор строки: s2- текущий символ предложения
3) Если s2 это операнд (число), то преобразовать его и поместить в Stack2 и перейти к пункту 2 алгоритма.
4) Здесь s2 это оператор и пусть s1 последний оператор в стеке Stack1.
Возможны варианты:
а) Если f(s1)<g(s2), то добавить s2 в Stack1 и перейти к пункту 2 алгоритма.
б) Если f(s1)>g(s2), то выполнить следующие действия:
I. вызвать программу обработки последнего оператора в Stack1, эта программа должна выполнять следующие действия:
- выполнить операцию s1
- сжать Stack1, то есть удалить оператор S1 из Stack1.
- сжать Stack2, то есть удалить 2 операнда, над которыми выполнялась операция S1 в Stack2
- поместить результат выполнения операции S1 в Stack2
II. Если s2 конец строки и стек Stack1 пуст, то завершить выполнение алгоритма, иначе к пункту 4 алгоритма.
в) Если f(s1)=g(s2), то удалить из стека Stack1 оператор s1 и перейти к пункту 2 алгоритма.
Пример изменения стеков
Stack1 и Stack2 для арифметического
выражения
1. Задано арифметическое выражение: А+В*С
|
|
операторы |
операнды |
|
|
|
Stack1 |
Stack2 |
|
|
2 |
+ |
А |
|
|
3 |
+ |
В А |
|
|
4 |
+ + |
В А |
s2=’*’ выполняется п.4а алгоритма |
|
|
* + |
С В А |
|
|
|
+ |
С*В А |
s2=’\0’ выполняется п.4б алгоритма (s1=’*’) |
|
|
|
А+С*В |
s2=’\0’ выполняется п.4б алгоритма, вызывается функция (s1=’+’) |
2 задача курсовой
работы
Разработать спецификацию программы восходящего распознавателя для грамматики арифметического выражения.
На вход распознавателя передается строка с предложением грамматики. Использовать или структурированный язык или flow form.
Максимально 2 страницы.
Это должна быть не программа, а спецификация.
Некоторые особенности языка SQL
Этот язык теперь является общесистемным по следующим причинам:
1- Этот язык являтся языком описания и манипулирования данными.
2- Выступает как средство взаимодействия серверов в распределенных БД.
3- Используется практически во всех СУБД с архитектурой клиент- сервер.
Существуют
стандарты:
1. В начале SQL92 (SQL2)
2.Сейчас действует SQL99 (SQL3)
Он включает в себя стандарт SQL92 и расширения для объектных реляционных СУБД.
Лекция 17
Пример схемы БД, используемой для иллюстрации
приложения на SQL
r=(S,P,J,SPJ)
S- ”Поставщик”;
- номер;
- ФИО поставщика;
- состояние его счета;
- город проживания и центральный офис
P- “Деталь”(описание поставляемой детали);
- номер детали(ключ атр.);
- название;
- цвет;
- вес(в фунтах);
- город(изготовления детали);
J- “Изделие”;
- номер_изделия(ключ атр.);
- название;
- город(изготовления);
SPJ- “Сборка”;
- номер_поставщика(поставляющий деталь, ключ атр.);
- номер детали(поставляемой поставщиком, ключ атр.);
- номер_изделия(в которое входит деталь, ключ атр.);
- количество(количество деталей в поставке);
Запись в таблицу SPJ.
ER диаграмма имеет вид:
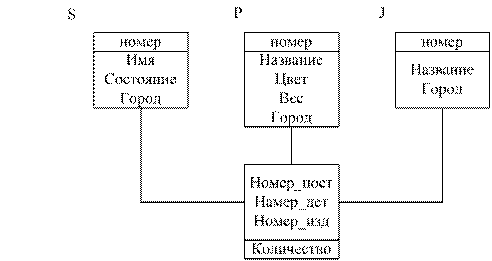
Язык SQL включает в себя язык описания данных и язык манипулирования данными.
Язык описания данных используется для создания объектов (таблиц, триггеров, пакетов, снимков), его рассматривать не будем.
В основном будем изучать язык манипулирования данными. Он имеет 4 оператора:
- Select- поиск и чтение записи из БД.
- Update – обновление существующих записей в БД.
- Insert – включение новых записей в таблицу БД.
- Delete – удаление записи из БД.
SQL относится к классу непроцедурных языков. То есть в операторах указано, что нужно сделать, но не как это сделать. Но часто этот непроцедурный язык используется в процедурных языках.
Возникает проблема импеданса- несоответствия модели языка SQL и модели проц. языков. Эта проблема решается с помощью курсоров.
Существует 3 варианта применения SQL в процедурных языках:
1) API-интерфейс (применяется специальная функция, в качестве аргумента указывается строка с SQL- предложением)
2) SQL- операторы встраиваются в проц. языки(PRO*C= C+SQL; SQLy=java+SQL)
3) Как обычные операторы процедурного языка, но возвращающие множество записей образованных с помощью курсора.(PL/SQL(Oracle))
Оператор SELECT.
Упрощенный синтаксис:
SELECT[DISTINCT] атрибут(ы)
FROM таблица(ы)
[WHERE условие]
[GROUP BY атрибут(ы)[HAVING условие 1]]
[ORDER BY атрибут(ы)];
Оператор SELECT моделирует выполнение операции реляционной алгебры ( селеция, проекция, декартово произведение и т. д.) В результате выполнения этого оператора строим новую таблицу, содержащую выбранные записи.
Порядок выполнения:
На логическом уровне.
1) Из исходной таблицы, указываемой за ключевым словом FROM, выбираются записи удовлетворяющие условию, указанному за ключевым словом WHERE.(Это операция селекции).

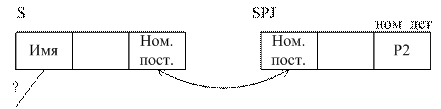



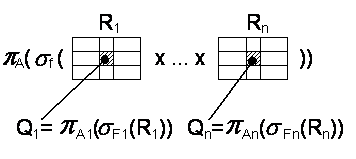
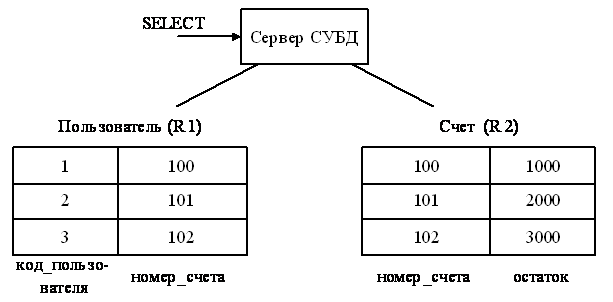
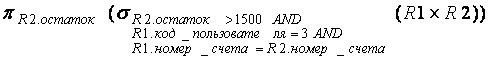


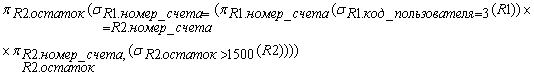 (5.3)
(5.3)
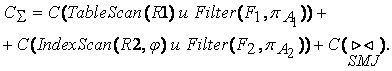


 (5.5)
(5.5) (5.6)
(5.6)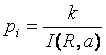
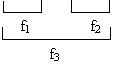
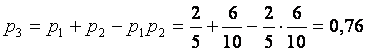
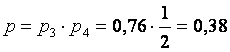
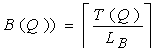
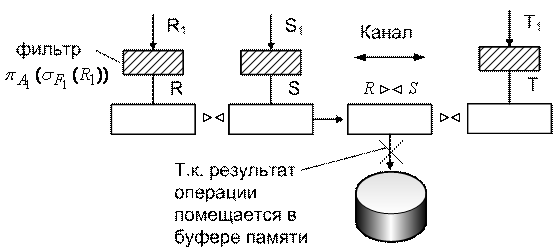

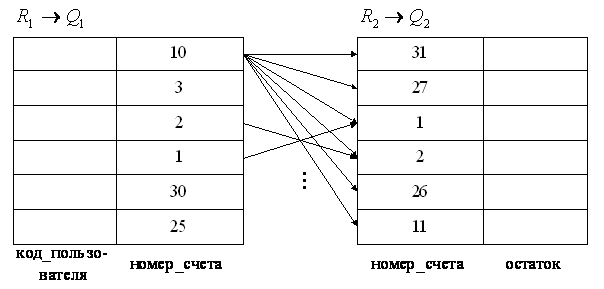
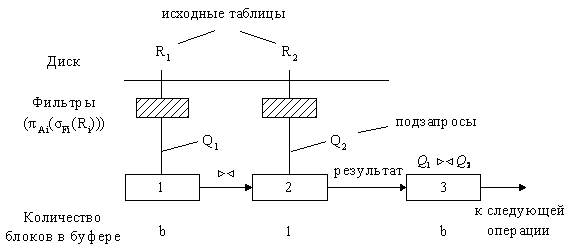
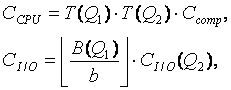

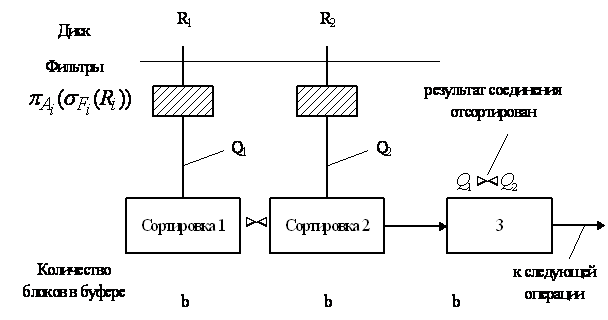


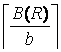
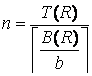 . С учётом числа файлов получаем первое слагаемое в формуле 3
(см. выражения (5.9)).
. С учётом числа файлов получаем первое слагаемое в формуле 3
(см. выражения (5.9)).